When Astera launched its life sciences division, Radial, earlier this year, we set out to reimagine how life science research happens at a systems level. Today we are announcing $5 million in seed funding to The Deliverome Project, a new fit-for-purpose nonprofit research organization building the toolkit to unlock a long-standing bottleneck in precision medicines: targeted delivery.

The Deliverome Project will create the first comprehensive, open-source, multimodal atlas of proteins on the surface of human cells. Precision medicine has long needed a high-quality, comprehensive dataset that not only catalogs these biomolecules’ specificity and abundance, but also characterizes their ability to traffic cargo into human tissues. But no one group has had the right combination of technology, institutional structure, and incentives to pull it off. The Deliverome, led by cofounders Becca Carlson and Bobby Hollingsworth, are up for the challenge.
Precision medicine’s missing data problem
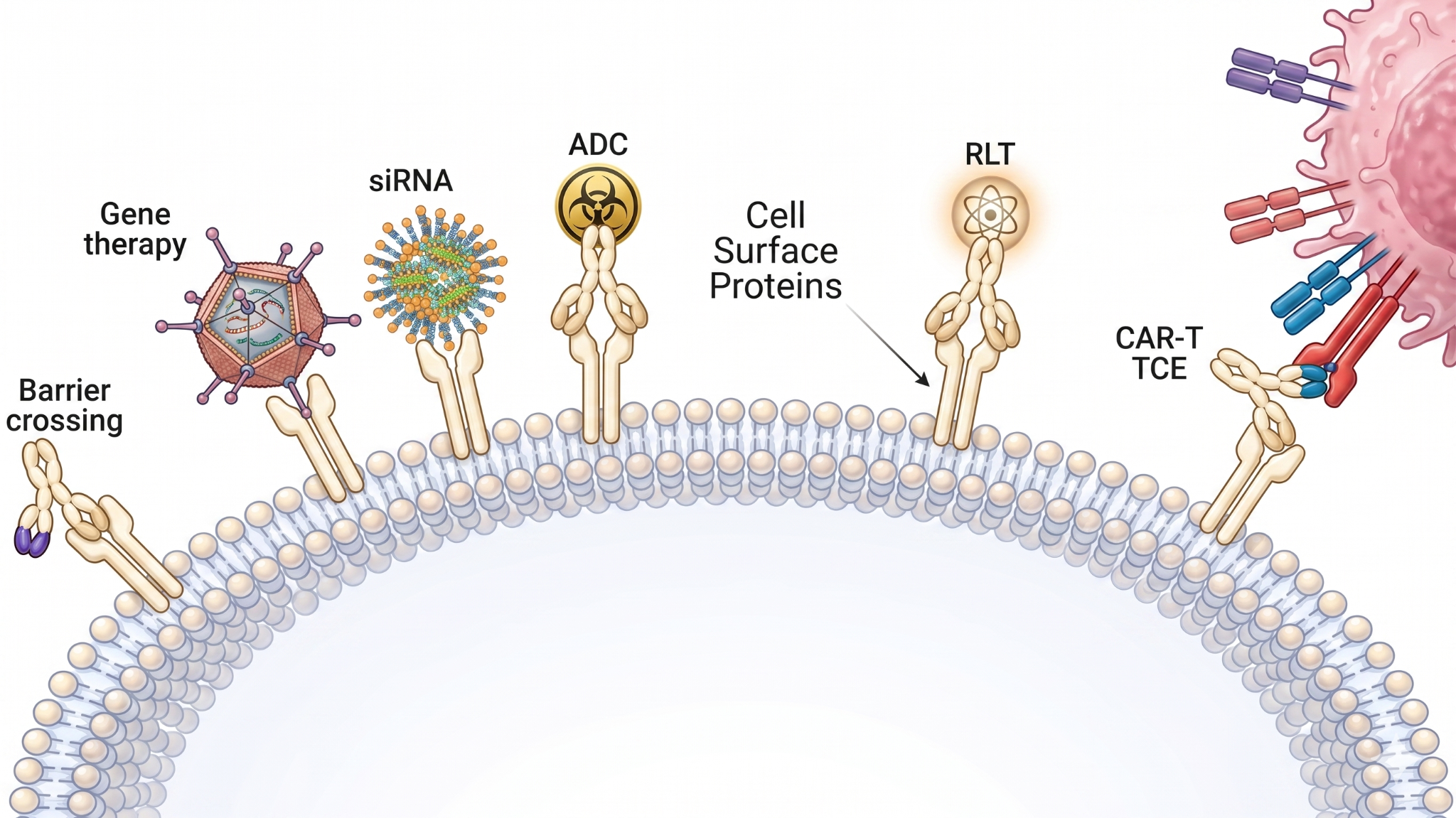
The payloads of precision medicine have never been more sophisticated. Today’s scientists can engineer CAR-T therapies for wiping out blood cancers; gene-editing to permanently correct heritable disease; RNA medicines that block harmful proteins from forming, and antibody-drug conjugates that destroy cancer cells while sparing healthy tissue. But precision medicine’s promise rests on our ability to get those revolutionary payloads to exactly the right cells in the body. Delivering cutting-edge therapy means inscribing the correct molecular address. And here, the field is flying blind.
The overwhelming majority of drugs in development today cluster around a small set of known, validated surface targets. That clustering isn’t a choice; it’s a data gap. Human tissues carry thousands of individual surface proteins; the vast majority (and their millions of pairwise combinations) remain undiscovered. Even for familiar proteins, biologists have little sense of how abundant they are across different cell types, or how they circulate cargo in and out of the cell. Neither a scientist nor an AI model can reliably predict which surface proteins will enable safe, effective delivery to a given disease.
A purpose-built, open-science solution
The Deliverome team will atlas the presence and nature of cell surface proteins using two increasingly sophisticated techniques. The first is mass spectrometry, which will measure surface protein abundance in different human tissue; the second will determine which proteins support cellular internalization of cargo. Both approaches are high-throughput by design. Deliverome will be able to interrogate thousands of surface proteins simultaneously.
The seed funding we are announcing today will allow the team to build out and validate the necessary technology platforms, hire a team, begin sample acquisition, set up computational infrastructure, and start sharing data. Any surface target the Deliverome maps may be the missing link for the next transformative therapy.
Deliverome’s methods and findings will all be released openly. Expect to find protocols, reagents, raw data, and analytical outputs shared continuously in AI-ready formats without waiting for journal publication cycles and with an eye towards reuse. The goal is to make the data generative for the entire ecosystem — every academic lab, every biotech company, every AI model building the next generation of precision medicines.
Why a dedicated nonprofit org is the right structure
Precision medicine’s glaring data gap on surface proteins is a too-common failure of the market. Pharma companies that build surface protein data keep it proprietary and narrowly focused. Academic labs lack the scale, coordination and incentives to execute at the required level. Venture-backed startups face immediate pressure to narrow to one therapeutic area, protect data as IP, and deprioritize the platform as they advance their first clinical asset. Everyone would benefit from a high-quality, comprehensive cell-surface protein atlas, but no one in the current system will build it.
The Deliverome Project requires the resources and freedom to pursue the full problem space: industrial-scale execution combined with an open science mandate. Radial’s mission is to experiment with what science gets done, how science is organized, and what science produces. Structuring this project as an FRO allows the Deliverome Project to meet each of these ambitions.
Ambitious science requires entrepreneurial, technical founders
The Deliverome’s cofounders Becca and Bobby each have a rare combination of deep technical fluency in experimental platforms, genuine conviction to open science, and the drive to build an organization from scratch. They bring with them years of experience in functional genomics and proteomics, cell biology and structural biology, platform building and target identification.
Becca’s PhD in the Blainey and Hacohen labs at the Broad Institute led her to develop single-cell genetic analyses called optical pooled screens. She then moved into industry to scale science into useful technologies, first at a spatial biology startup and then in venture creation at Flagship Pioneering. Time after time, she noticed the same obstacle: platform biotechs had powerful delivery technologies, but their target data was too weak to actually deploy a therapy.
Bobby’s path is complementary. His doctoral work with Hao Wu at Harvard investigated innate immunity with cryo-EM; and his postdoc with Wade Harper added spatial proteomics to his repertoire. Before Arena BioWorks’ closure last year, Bobby worked on their team identifying novel surface targets across disease areas. But beyond his technical background, Bobby’s long-standing commitment to open science inspired us. As a postdoc, he shared work publicly outside even traditional preprint infrastructure; at Arena BioWorks, he pushed the company toward a more open posture on their science; and recently when receiving the Experiment Foundation’s Beyond the Journal award, he responded to the news simply with “I don’t need the money, this is how I’d operate anyway.” That orientation is central to the Deliverome Project’s mission.
Both Becca and Bobby’s careers have been building toward this project. We’ve been impressed by their conviction, their speed, their ability to absorb and incorporate feedback, and their fundamental orientation toward building useful science that works for everyone. Additionally, Becca and Bobby’s detours through the applied world of platform biotech and drug discovery are a feature, not a bug. That experience sharpens their sense of exactly what’s missing and why it matters. There are very few places designed to support researchers who want to go back to the sandbox and address fundamental problems with this kind of clarity. We think that’s the profile this work demands, and it won’t be the last time we look for founders like them.
What comes next
Becca, Bobby, and their team will not be able to solve this problem alone. The Deliverome Project will require partners across areas such as human tissue sample sourcing, methods development, computational biology, and the broader biopharma and academic ecosystem. Inherent to the open science commitment and desire to build a truly useful resource is an appetite for feedback from the research community.
If you’re a researcher working on precision delivery, a clinician with access to annotated tissue samples, a company with relevant platform capabilities, a scientist building off of our open work, or a funder who believes public-good data infrastructure in biomedicine deserves more serious investment, we want to hear from you.
To learn more about The Deliverome Project, visit deliverome.org
Get in touch at contact@deliverome.org

Thousands of feet below the surface of the Pacific Ocean, a sea sponge produces threads that lattice together into a translucent skeleton. A foot-long glass house of their own design. When Tim McGee, now a resident at Astera Institute, learned about this creature — the Venus flower basket — in 2003, it changed his career. McGee left a job in pharma to work with a lab studying how sea sponges could do such a thing. It was an amazing feat of manufacturing completely unlike anything human technology could do.
“It just kind of melted my brain that at the bottom of the ocean there’s these creatures that are spinning glass, whereas we have forges at thousands of degrees,” McGee said. “It’d be amazing if we could do that.”
McGee has since devoted his career to learning from nature’s ingenuity and the power of proteins.
When nature assembles proteins carefully at the molecular scale, it creates strong, responsive, and smart fibers, because proteins can sense and respond to their environment. It’s a sort of material intelligence. But our manufacturing falls short. Our usual fibers don’t have the variable attributes that proteins do; and when we do try to build with proteins, our fiber assembling processes fall far short of nature.
We cannot yet program the exact combination of properties we need, be it strength, conductivity, transparency, and so on. Think of robots actuated by fibers that move like our own ligaments and compute a sense of touch. “How can proteins basically be a way for us to make almost anything?” McGee said. In his residency with Astera, he is working toward that future.
McGee’s Impossible Fibers program is creating a manufacturing technique to make protein fibers that more closely mimic nature’s tactics.
“We know nature can create tunable structures,” McGee said. “The question is, how do we start to get there? And how can we get there quicker?”
The problem with traditional fiber spinning
If you want to spin fibers out of proteins today, your options are limited. Manufacturers either melt and resolidify polymers (melt spinning) or extrude polymers from one solution into a bath that coagulates them into thin filaments (wet spinning). Neither method allows for adequate molecular assembly of proteins. They instead essentially force a material into a particular alignment. Whatever special attributes they need must then come from the usual chemistry levers: high or low molecular weight polymers and potentially toxic additives introduced after spinning.
But proteins are too finicky for this approach. Proteins want to align and bond in their own particular way. “The way that we manufacture today is akin to just supergluing everything together and throwing it out there, as opposed to actually assembling the Lego bricks,” McGee said.
With Impossible Fibers, McGee is seeking more control over how proteins assemble in space and time.
More precise control with encapsulation
Impossible Fibers’ proposed system begins with “encapsulation,” inspired by how creatures like spiders, mussels, and velvet worms store, sequence, and trigger protein assembly.
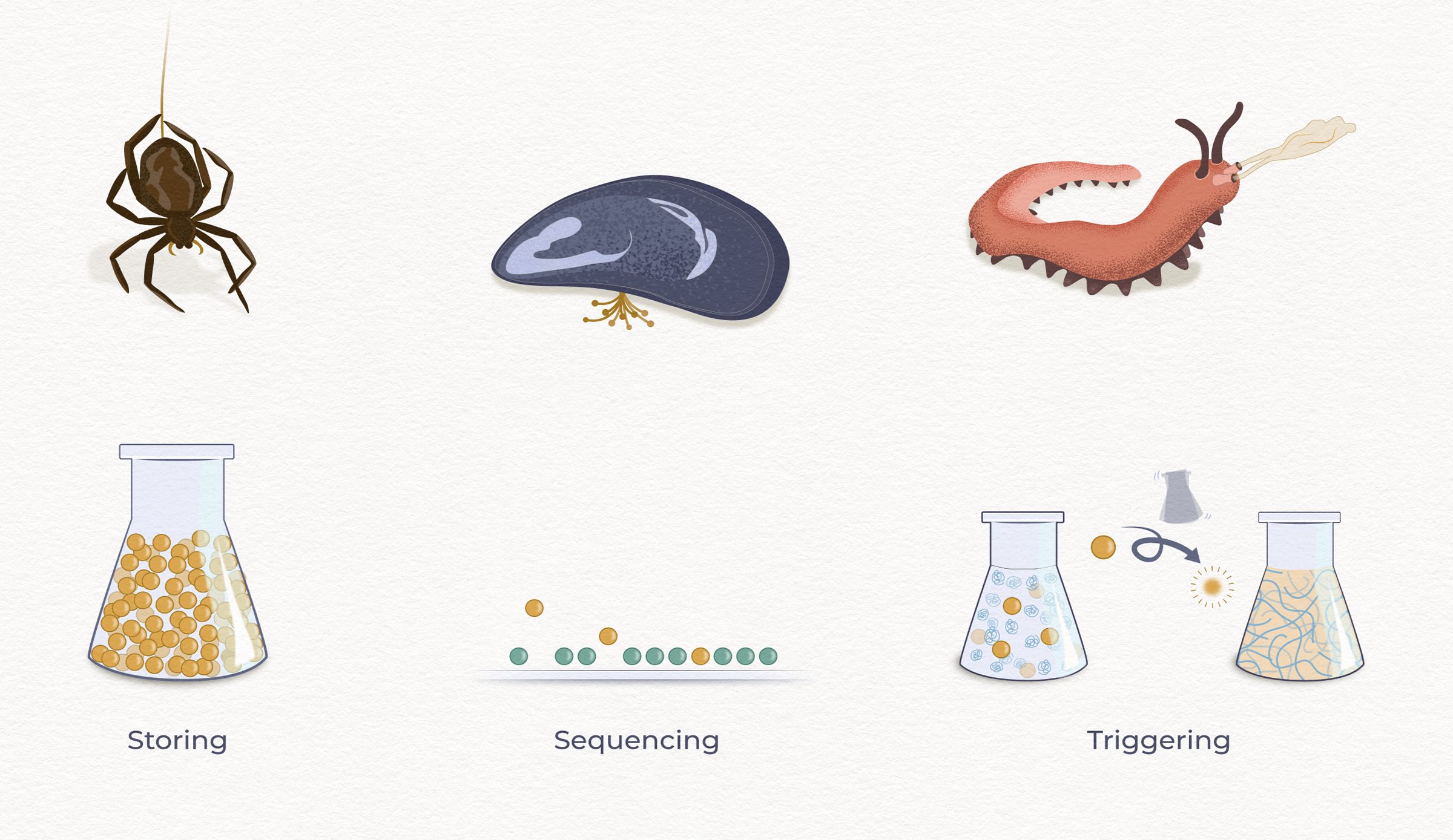
The team is prototyping a three-part platform. First, a microfluidic device encapsulates small droplets of dissolved proteins, transforming them into stable droplets. The droplets can then be arranged, sorted, manipulated and programmed into desired arrangements, like beads on a string that program how the material is assembled. A third device then bursts the droplets and precisely assembled fibers from its proteins.
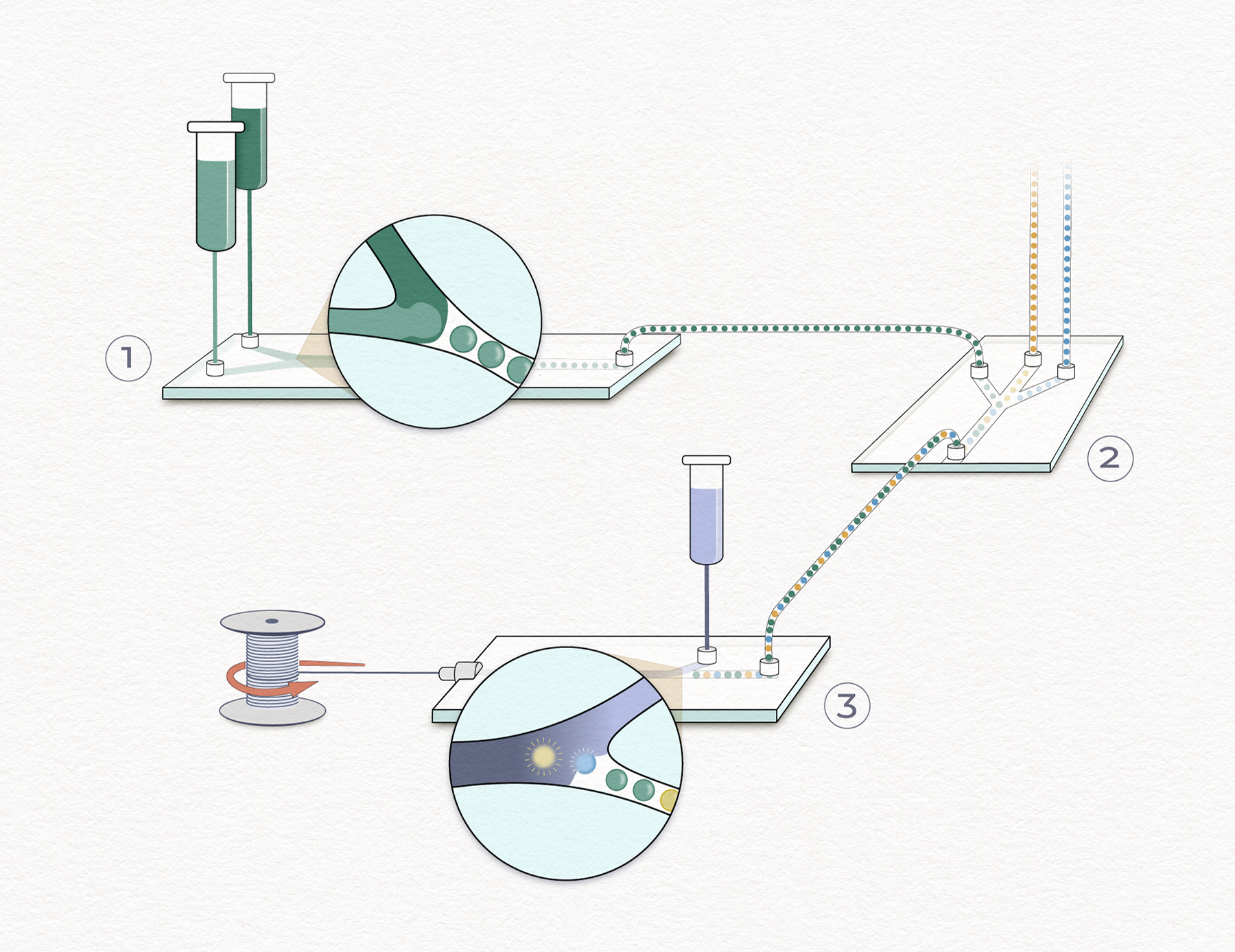
“You can pop them at the right moment,” McGee said. “So we do reactions in this microfluidic device, and then we pull a fiber out of the other end.”
This is the kind of control that scientists often see in nature’s high performance fibers.
Encapsulation gives unprecedented flexibility
McGee envisions the same encapsulation platform for programming fibers out of any number of different proteins. And that generalizability is important.
Fibers are everywhere, and the need for high performing multi-functional fibers is everywhere as well. Companies have spent decades trying to engineer spider silk for strong, lightweight materials. And the upside is about more than strength. AI companies would benefit from hollow core optical fibers which transmit data through narrow tunnels of air, rather than glass; roboticists would benefit from strain-sensing and conductive filaments which could unlock proprioception and more human-like function. “Whether it’s optical, electrical, mechanical, chemical, or just adaptable,” McGee said, “All those things you can do with proteins.”
It’s unrealistic to expect a one-size-fits-all fiber spinning platform. But this type of encapsulation platform gives manufacturers an unprecedented generalized step inspired by nature to begin protein assembly.
Why here
Impossible Fibers is following in the footsteps of prior Astera residents, by identifying a daunting bottleneck that, if resolved, will ripple transformation across tech sectors that would not have the opportunity to innovate so drastically.
Impossible fibers is the quintessential project that falls in the gap between academia and industry. Academic labs have shared some of Impossible Fibers’ ideas, but seeing that vision through requires a scope and scale beyond academia’s abilities. On the other hand, venture investors won’t touch a high-risk capital intensive project without a clear, focused application. But that’s precisely why previous protein fiber groups have failed: they are forced to use existing manufacturing in order to fit existing markets, effectively abandoning the unexplored terrain that made proteins interesting in the first place. The unique advantage of Astera is that philanthropic resources can de-risk these “boring” process components overlooked by traditional investment, while also taking bigger swings than what’s possible in academia. It’s the starting point for investors to see what might be possible if we invested in novel manufacturing through Open Science. Other labs or start-ups can then build on our work to advance the thousands of possible areas of focus.
“It’s kind of a rare program where they give you a salary and a stipend to build a lab to let you build out this capability,” McGee said. As an Astera Resident, McGee’s Impossible Fibers program will challenge old ideas of what fibers can be and what they can do. Multifunctional fibers could trigger a new era in robotics and unlock more durable and effective medical devices. McGee expects protein fibers to find use as implantable brain electrodes that more reliably match the soft, strong, conductive environment of nervous tissues.
Building openly, for now and the future
As Impossible Fibers works towards catalyzing fiber tech and new applications in the year with Astera, they are designing with open science in mind. The team is developing new microfluidic designs, new tools to prototype fiber spinning, and new methods to assess the protein fibers they spin. “Everything we are working on is open,” McGee said. “We believe this can foster a community of people to explore this exciting new frontier.
Why is this technological transition possible today, rather than five years ago or five years from now? For one, laser etching and 3D printing costs have decreased. But perhaps more important is the feedstock. We can make larger quantities of biopolymers — the building blocks for programmable materials — than ever before. Engineered bacteria can produce interesting proteins found elsewhere (and nowhere) in nature. Prototyping that previously would require millions of dollars and years of development can now be tested in weeks for tens of thousands.
It’s therefore urgent that we invent new manufacturing processes for this next generation of materials.
McGee hopes the work will lead to predictive algorithms to assist in biomaterial design. “It’s the vision of the far future,” McGee said, “of being able to ask an AI, I want a material with these properties, give me the protein and the manufacturing sequence to enable that to happen.”
This potential to master protein design may even allow us to surpass what nature can do. “Nature is not a perfect solution,” he said. Evolution is a messy, path-dependent process of incremental steps. The goal of Impossible Fibers is to extract the math, physics, and chemistry behind the most clever phenomena. “If we want to make the future faster, we have to figure out how to compress what we can learn from the natural world into our own technologies.”
Want to dig deeper? Visit the impossiblefibers.com and follow along at iflab.substack.com

A new era of power generation is coming with nuclear fusion. Fusion technology mimics the enormous flux of energy powering the core of the stars like our Sun. Small atoms smash together under such immense pressure and temperature that they fuse into heavier elements. The process liberates roughly four million times more energy per kilogram than burning fossil fuels.
Make no mistake: Fusion is a hard problem requiring immense innovation. But the energetic upside is compelling. If fusion power can reach 1 cent per kilowatt-hour — 5 to 10 times cheaper than today’s cheapest new-build power generation — it may enable other world-altering technologies, from affordable desalination and interplanetary space travel, to other leaps we can’t yet readily imagine.
Dozens of companies and governments around the world are betting on nuclear fusion to revolutionize how we power life on Earth. But despite $10 billion of investment, the road to these transformative promises is economically cloudy.
The interesting question is not really what life could look like with one cent electricity, but rather what sequence of events would make it possible? What needs to be true to achieve 1¢/kWh?
“It’s a wildly aggressive target,” says Damien Scott, a technologist working on fusion systems. “It may well be implausible.”
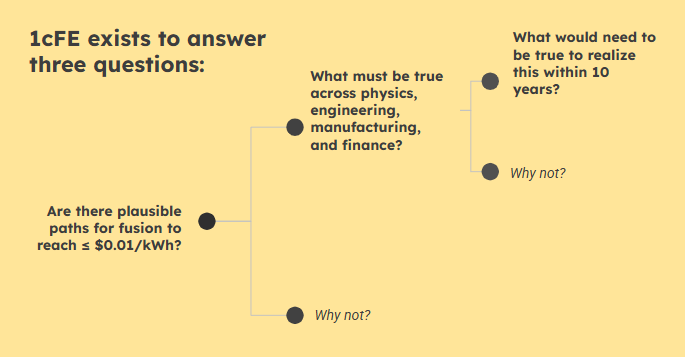
In 2025, Scott began a residency at Astera Institute to lead 1cFE, an initiative that models the potential costs of fusion energy, and determines whether (and how) any technologies have a path to 1¢/kWh electricity within 10 years. Scott’s goal is to understand what constraints limit the various scientific routes toward sub-cent fusion, resolving to make them visible before years of effort and billions more dollars pour in.
Many paths to cleaner energy
Scott’s interest in electricity came out of necessity. He spent his childhood years living off the grid on a remote farm in Botswana, forty miles from the nearest gas station. The wet seasons could wash out the roads, cutting them off further. Scott and his family learned to improvise. They drilled wells for their water, and jerry-rigged 1990s-era solar panels for power.
He later studied concentrated solar thermal power while earning a degree in applied physics at the University of Sydney, gravitating toward engineering projects that worked under harsh conditions. This led him to Williams Racing in Formula 1, where he helped create the team’s applied technology division. It was an extreme environment for engineering. F1 requires rapid iteration, unforgiving constraints, with constant high-stakes (and public) feedback. Scott went on to found an autonomous and electric vehicle fleet simulation and optimization startup, Marain. And these experiences crystallized his philosophy as a technologist: Before building expensive hardware, model enough to reduce uncertainty. In other words, Model twice. Spend once.
Marain was acquired by General Motors. After spending two years at GM Scott departed and began exploring what problems to work on next. “I kept coming back to fusion,” he says.
He studied the landscape and was struck by the quality of privately funded engineering teams in the space. The technologies were promising. But he couldn’t find a clear measure of how promising. “If we take the culmination of the last 75-80 years,” he wondered, “if this all goes according to plan—how cheap could it be?”
Wayfinding in fusion
Right now, the future of fusion is like a summit hike through dense forest. Many paths exist, some more delineated than others thanks to the hard work and good fortune of early trailblazers. But each tortuous trail faces unique obstacles.
In order to reach the right extreme conditions to achieve fusion on Earth, some use lasers to rapidly compress fuel. Other technologies use magnets to confine plasma. Nuclear fusion releases energy as electromagnetic radiation, fast moving ions and neutrons. What researchers do with that resulting burst of energy also varies. Many proposed fusion plants resemble current fission plants: They generate heat, boil water, spin turbines, and funnel electricity into the grid. Alternatively, a new model for plants could convert the energy of fast moving ions directly into electricity: plasma expands against the magnetic field that’s confining it, which induces a current.
Two feasibility metrics are particularly important when comparing technologies at the experimental stage: the triple product and the gain. Triple product represents the threshold plasma density, temperature, and confinement time required for a technology to trigger fusion Gain measures how much more energy a technology creates with fusion compared to the amount of energy it needs to start and sustain it. Small-scale experiments at Lawrence Livermore National Lab have yielded greater energy (8.6 MJ) than that delivered by a laser (2.08 MJ). This represents a theoretical, “scientific gain,” as opposed to the engineering gain or “plant gain,” for a whole facility. The inefficiency of the Livermore Lab laser makes it so that the system still uses much more energy than it generates.

As an Astera resident, Scott’s 1cFE is building open-source cost models that compare these many paths on the basis of their potential upsides and constraints. For example, analyses peg the floor of fusion systems relying on steam generation at 0.5¢/kWh. “The cost of steam turbine processes really constrains,” Scott says. “It may be harder for fusion approaches that generate heat to get to that one cent target.” Direct energy conversion bypasses the costs of steam boilers, but it requires different fuels and less well-studied physics and engineering.
Tradeoffs like this are not necessarily dealbreakers. No leading technologies have yet been ruled out of the one-cent pursuit. But the optimal approach at this point in fusion’s development is to carefully scrutinize how we’ll reach one cent and beyond. And that, according to Scott, requires working backwards.
Frontier backcasting
As of 2025, no private company has demonstrated scientific gain above 1. Some are approaching, with forecasts of hitting scientific breakeven next year. We are seeing new facilities break ground every year with private-public partnerships. Several companies claim they will have carbon-free power plants online before 2030, and tech giants like Google and Microsoft have already signed power purchase agreements.
The hope to finally deliver fusion electricity after decades of work has never been higher, Scott says, but his ambitions aim even higher. 1cFE’s role is to investigate the plausibility of sub-1¢/kWh fusion power. “Solar is a very instructive analogy, because the fuel cost is zero, very similar to fusion where the fuel cost is minimal,” Scott says. “We can do solar plus storage at 5¢/kWh, and that is getting cheaper.” The key innovation lies in how to manufacture the device that produces electricity not just cheaply, but cheaper than anything else.
Hitting 10¢/kWh would make fusion competitive in some markets. At 5¢/kWh, the market balloons toward profound change. But at or below 1¢/kWh is where the more profound changes can emerge — it’s an anchor that exposes the limits facing fusion technology.
1cFE begins with this target, then asks what would have to be true — in physics and economics — for that world to exist. This so-called “frontier backcasting” reveals constraints and the required levers.
Frontier backcasting helps focus a subset of the field’s research, investment, and policy, toward the most aggressive end goals by exposing what’s actually possible. “It is common to overestimate what is possible in one year and underestimate what is possible in ten,” Scott says. Consider the fallen cost of launching payloads into low Earth orbit. Between 2000 and 2010, LEO launches hovered between $8,000 and $12,000 per kilogram. SpaceX sought to lower costs by an order of magnitude. But this would not be possible with incremental innovations. It was only possible with unprecedented reusability. Their bold target forced them to consider an entirely different gameplan, and today reusable rockets have already cut costs by a factor of 10.
“Which levers are unavoidable to reach 1¢/kWh?” Scott asks. “We will use this target in fusion to expose how far the levers must move, and in what order.”
Estimating uncertainty
1cFE will help compare different approaches to reaching cheap electricity. The current landscape of proposals includes mature technologies with relatively predictable lifetime costs as well as much newer technologies that are harder to quantify.
So how will the team quantify approaches comprising such varying degrees of uncertainty?
The first layer of modeling estimates capital cost, interest, operational costs, and learning rates — the change in cost that comes over time with more production experience. They also assign a “technology readiness level” to subsystems or components. “If it’s a laser that has only been made once, that’s on the lower end of the TRL scale. Whereas, if you are reusing fast-switching capacitors found in a bunch of other industries, that’s much higher.”
But what about components that simply don’t yet exist? Although the cost of new concepts that depend on not-yet-invented technology are more difficult to quantify, 1cFE’s modeling can benefit here too. Rather than guessing what unproven components will cost, the team inverts the question: working backwards reveals what those components would need to cost to make new ideas viable. “How cheap does your accelerator need to be?” Scott says. “If it’s half-mile long, that is going to propagate into the cost of your land.”
Outputs
In a one-year residency with Astera, Scott is leading a team with expertise in physics, systems engineering and software to create models, outline assumptions, and identify both promising and discouraging roadmaps.
Like other Astera residencies, 1cFE aims to unlock a future of abundance and human flourishing. The typical Astera project leans into the messy uncertainties about how technology will evolve. For 1cFE, this means applying rigorous cost analysis and technological assessments to expose a plausible path to abundant energy. This is a path to innovation that has too often been neglected in favor of incremental improvements. And 1cFE’s approach is open-science from idea to result: They will publish everything, including negative results as well as fully transparent corrections. “We encourage others to find errors, and we will correct them as we go,” Scott says. “The commitment is to keep the record honest and not just open.”
Later this year, 1cFE will deliver the first systematic, open-source techno-economic comparison of fusion pathways against a sub-cent target. They will publish datasets, a report benchmarking new AI tools, and reproducible code. Scott envisions a public dataset listing 10 to 15 fusion concepts and the technoeconomic conditions required for each of them to reach 1¢/kWh.
They will run two workstreams in parallel: backcasting to the technical, industrial, and policy constraints implied by a one cent target; and testing where AI can accelerate the design-build-test-learn cycle.
Researchers have already published a lot of useful fusion information, but data is largely fragmented across formats that don’t lend themselves to quantitative, and prospective comparisons. 1cFE is building the missing layer: a dynamic database of levelized costs across approaches. The team’s technoeconomic assessment will make it cheaper to add concepts, rerun analyses, and compare approaches side-by-side.
For companies interested in targeting 1¢/kWh, 1cFE’s work will help identify a path forward. The goal is not to prove out or favor any particular confinement system or fuel choice; it is to slash uncertainty so that technologists and investors pursuing ultra low cost fusion can direct resources into the ideas most likely to radically change humanity.
“Fusion is frequently described as clean, limitless, and virtually free,” Scott says. “Those words need to be quantified.”
Follow the project: 1cfe.substack.com | github.com/1cFE | @1cfenergy on X
Today, Astera Institute is launching Radial, a division which reimagines how life sciences research happens at a systems level. Radial will be led by Becky Pferdehirt as CEO. We are committing up to $500M over the next decade to expand our build-test-learn approach to scientific infrastructure and practices.
How we fund, do, and build upon science in the U.S. has long needed an update. We’re at a historic inflection point with AI acting as a forcing function on biology — not because it will immediately solve hard problems, but because its demands and widespread adoption will, increasingly, expose how unfit for purpose our scientific infrastructure actually is. We also have more tools than ever before to find new solutions. But positive change isn’t inevitable, which is why Astera is expanding its efforts through Radial.
Radial is grounded in two key beliefs. First, scientific practices for impactful discovery—from how we design methods to how new knowledge is shared and translated into real-world use—need to be rebuilt from the ground up. Second, it’s very difficult to go about this without deliberate iteration through active research efforts. In other words, we need to experiment with how science is done through actual science and scientists.
Our starting framework
Radial is going to try a broader range of things in the beginning that will drive our own evolution. We will be looking for more radical experiments that can give more information about what’s possible, regardless of whether they succeed or fail in the classic sense. We will iterate on:
- What science gets done.
We are thinking about what gets funded as well as what scientists decide to work on in the first place. We have more ways than ever to traverse the white space with data and modeling, not just opinions and trends. And we’re happy to work with anyone and any sector that prioritizes impact, utility, and metascience experimentation.
For example, we’re working with industry partners to leverage existing tools and laboratory infrastructure to generate open, high-quality datasets. With OpenADMET, we are characterizing small molecule properties—ADME and toxicity—that can be explored and trained on for real-world utility. We think there could be more general potential here: leverage unique cutting edge platform capabilities from start-ups and point them at public good problems. It’s kind of the inverse of Focused Research Organizations (non-profit start-ups), and we think there could one day be a more generalizable model here that addresses distinct gaps in a complementary way.
- How science is organized.
Our institutions are built for an era that emphasizes discrete projects and individual achievement. Many scientific challenges today require truly multidisciplinary or multi-sector teams holistically redesigning all components of technical systems (data, methods, and projects). This requires a lot of time, experimentation, and willingness to step outside dominant incentive structures to first figure out what works.
As an example, The Diffuse Project is our first major in-house program for understanding protein motion by co-developing the necessary experimental methods, computational models, data standards, and infrastructure. Our goal is to make dynamic structural biology data as foundational as the Protein Data Bank has been for static structures and to scale the data through broad methodological adoption.
- The outputs of science.
To accelerate scientific progress, we need to realign our infrastructure, metadata, and research artifacts around how AI-empowered scientists will actually work. We also need to build interoperable solutions so that advances compound across the ecosystem. We’re at a rare moment to shed the historical constraints on research sharing that have kept science from reaching its potential. The path forward is full of unknowns, which is where we feel most at home: testing what others don’t yet have the chance to try, and sharing what we learn along the way.
Among many other efforts, we are currently developing The Stacks, an open-access digital platform to experiment with how scientific, technical, and intellectual work is shared and discovered. It’s a publishing infrastructure prototype that we hope to innovate upon to help iterate towards what science actually needs from first principles for machine readability, rapid iteration, and genuine reuse.
Why now?
While we’ve been working in this area for a few years, we’ve needed a few things to fall into place before expanding. First, we needed to try a bunch of approaches to develop conviction around a starting framework worth expanding on. Second, we needed the right leadership team to take it to the next level.
I could not be more excited to share that Becky Pferdehirt has joined as Radial CEO. I’ve known Becky for over a decade and watched with admiration as she’s successfully worn many different hats as a scientist. Becky joins from Andreessen Horowitz, where she was an Investing Partner at a16z Bio + Health. Becky was previously an R&D Scientist at Genentech and held research and business development roles at Amgen. She has a PhD from UC Berkeley and a BS from MIT. If you’ve ever interacted with Becky, you also know that she is an exceptionally sharp, creative, and flexible thinker who acts with integrity – all critical for quickly imagining and exploring new directions for basic and translational science. Becky will be working closely with me and Prachee Avasthi, our Head of Open Science, as she takes the reins on Radial.
Joining her is Stephanie Wankowicz as Scientific Program Director of The Diffuse Project, our research initiative focused on protein dynamics. She will be leading its expansion. We are so grateful to Stephanie for fully taking the leap from her current post at Vanderbilt University, where she ran her own lab developing computational algorithms to model conformational ensembles from X-ray crystallography and cryo-EM data.
Becky and Stephanie will be working closely with several others, including Sekhar Ramakrishnan, who joins from The Swiss Data Science Center as Engineering Lead for The Stacks, our experimental publishing platform that we are developing and building through programs like Diffuse. Steven Moss has also joined us from the National Security Commission on Emerging Biotechnology as a new full-time Science Policy Associate to help think about how we scale change at a national level.
Join us
Radial is adaptable by design. We are building programs in-house, funding external teams with multi-year grants, investing in companies, and designing public-private partnerships across government, academia, and industry. We’re looking for people who are willing to take risks and treat informative failures like a badge of honor.
For all of our roles, we’re excited about candidates who will lead by example, shifting perceptions of what’s possible before it’s popular to do so.
For technical leadership: We’re searching for a Head of Bio AI to lead AI across Radial programs. [Apply here]
For structural biology and protein dynamics: Scientists, engineers, and operators for the Diffuse team. [Apply here]
For ambitious ideas that need space: Astera’s 2026 residency program has slots for projects that don’t fit existing funding models. [Apply here]
For new models of partnership: Companies, national labs, academic institutions—if you’re thinking about how your capabilities could be pointed at public-good science, let’s talk.
For working scientists facing bottlenecks: We’re launching an essay competition inviting active scientists to describe a concrete research challenge caused by structural bottlenecks, and experimental strategies to fix them. [Learn more.]
Get involved:
- Join the team: Open positions
- Residency program: Apply by April 19th
- Partnerships: Contact us
- Essay competition: Tell us about your bottlenecks
Today, alongside the launch of Radial, we are opening an essay competition that I’ve been ruminating on for some time. Namely, inviting active scientists from any sector to share concrete research challenges that can inform our future work at Astera. We’re interested in your hypotheses about what broad structural or systemic issues contribute to the bottlenecks you experience in your own science. It’s important to me that we hear more from active scientists on the ground.
Many of our scientific systems and institutions are no longer fit for purpose. How we fund work, share results, build teams, and connect science to other disciplines or sectors has long been in need of experimentation. This is no longer a controversial statement.
We are living through a historical inflection point that demands change. One force is technological, happening at unprecedented scale and speed. AI is making it harder to ignore systemic and infrastructural gaps, while also changing what solutions are possible. This is an incredible forcing function we should leverage to update our scientific practices.
At the same time, it’s become harder to talk constructively about change in light of political differences and more recent budgetary contractions. But it’s more important than ever to openly debate long-term reform now. And many disagreements are unlikely to be resolved through debate in the absence of real life testing.
We’re looking to you, scientists
The field of metascience, i.e. the science of science, is often driven today by non-scientists: policy experts, economists, sociologists, psychologists, historians, politicians. Their work can be very useful, but practicing scientists should be more deeply involved in shaping the systems they depend on.
Scientists know first-hand what is broken. When scientists themselves have led metascience experiments, the outcomes have often been distinctive and more durable: new institutes structured around questions; focused research organizations built to unlock specific field-level bottlenecks; community infrastructure launched because there was simply no other way to make it happen; critical resources that can’t wait for permission.
We want to help get more scientists in the driver’s seat of this conversation and source more hypotheses that can be tested for systemic improvements. We want all of it to happen in the open to stimulate more useful public debate about science. And we hope that will help the most compelling ideas get real world implementation through support from us or others.
Examples of what we’re looking for
Perhaps an easier way to explain what we’re looking for is to highlight a few historical examples that we would have loved to fund early iteration for. Here are a few:
- The Protein Data Bank
A few crystallographers were frustrated that hard-won structural data was disappearing into individual labs with no way to share it. They bootstrapped a community archive in 1971 with just seven structures and no formal institutional mandate. We would have loved to award an essay describing this gap and fund the early bootstrapping required to prototype the foundational data infrastructure for structural biology and drug discovery worldwide.
- arXiv
The scientist Paul Ginsparg noticed that his colleagues were emailing preprints to each other and built a centralized server in 1991 to do it better. We would have loved to award an essay describing this gap and fund the initial server required to test the utility of what became today’s default open publishing infrastructure for physics, math, and computer science. It has since become a general model for the broader open-access movement.
- Focused Research Organizations
Two scientists, Adam Marblestone and Sam Rodriques, were dead set on trying to generate more connectomics data as a critical public resource for the neuroscience community. This was a defined roadmap that required a start-up-like team, which lacked any dedicated funding mechanism. So they created one by inventing FROs, and it has become an enabling structure for many other projects with similar properties. We would have loved to fund early iterations of FRO projects (and we did through the first FRO: the longevity-focused Rejuvenome!).
- Arcadia Science
This one’s an experiment I’m directly involved in that’s still in a work-in-progress. Arcadia is a for-profit research company co-founded in 2020 by myself and another scientist, Prachee Avasthi. It was motivated by trying to reimagine how we could more effectively traverse a wider swath of biology for useful discovery than was possible in our academic labs. We asked how we could use data to develop organism-agnostic tools, compound broader lessons by sharing more of our work in real time, and open up new funding and sustainability strategies. It would be exciting to fund smaller scale pilots that could inform experiments that lead to new institutes, which can and should be less monolithic than what dominates today.
I hope more scientists will join us in this dialogue, which is why I’ve asked that all submissions are public. I know it can sometimes be uncomfortable to put your neck out in this way, but positive change is more likely if we normalize open debate. We should approach all disagreements according to the scientific principles we were trained on. Data, not drama: let’s do the experiment.
See more details and apply here by May 1st.
Dileep George is joining Astera as Head of AI, leading our AGI research division. Working alongside our Chief Scientist Doris Tsao, he and the team will explore novel, brain-inspired computational architectures to accelerate the development of safe, efficient and aligned AGI. Astera will continue to support this effort with over $1 billion in committed resources over the coming decade.
Dileep joins from Google DeepMind, where he worked on frontier AGI research on agents with memory, planning and structure learning. Throughout his career, Dileep has shown that drawing on the computational principles of biological intelligence opens up novel, high-impact pathways for AGI research. At Vicarious, he scaled algorithms for visual processing and reasoning, gaining worldwide attention for breaking text-based CAPTCHAs with human-like data efficiency. He also pioneered AI-powered robotics as a service for industrial applications. At Numenta, he co-developed Hierarchical Temporal Memory, the theoretical framework modeling how the neocortex learns and reasons.
Dileep joins Astera alongside Miguel Lázaro-Gredilla, previously a Research Scientist at Google DeepMind. As Research Lead, Miguel will spearhead the development of world models that utilize hierarchical latent variables for long-horizon planning and robust reasoning.

Neuro-inspired AGI research is underexplored relative to its potential
The overwhelming majority of AI research today pursues a dominant paradigm: scaling transformer architectures trained on massive datasets. This approach has produced remarkable results and will likely continue to do so, but concentration around any single research direction leaves promising alternatives underexplored.
The principles of biological intelligence likely offer novel approaches to AI engineering at scale that aren’t captured in existing research paradigms. This could help address two sets of challenges that remain on the path to AGI:
1. Current AI systems lack fundamental capabilities that biological intelligence demonstrates. They can’t handle long-range planning that requires maintaining coherent goals across complex action sequences, or learn continuously from experience the way humans do. Massive datasets are still required for tasks where humans need only a handful of examples, and they continue to fail to generalize robustly to situations that differ meaningfully from their training data.
2. The safety and alignment challenges posed by current architectures remain unsolved, even as we continue to scale them. We don’t yet know how to build systems whose goals stay aligned with human values as circumstances change in ways they weren’t trained for. We can’t reliably interpret why models make the decisions they do, which makes it difficult to predict or prevent failures.
Commercial investments currently concentrate on scaling transformers, which risks trapping the field in local minima: optimizing a single approach while leaving vast parts of the solution space unexplored. Biological intelligence offers computational principles that current architectures don’t capture, opening pathways to systems that are more efficient and more naturally aligned with how humans think and perceive.
Bridging neuroscience and AI engineering
Efforts to map biological intelligence — how the brain constructs perception, cognition, and intelligence itself — remain disconnected from the engineering of AI systems. Neuroscience and AI research proceed largely in parallel with limited integration.
Providing decade-scale commitment and computational resources, Astera is running two research programs in tight integration:
- Decoding the brain’s computational architecture: Led by Doris Tsao, Chief Scientist for Astera Neuro, our Neuro division is working to decode the fundamental mechanisms through which the brain constructs intelligence. These capabilities represent some of the hardest unsolved problems in AI, and the brain solves them with remarkable efficiency.
- Building AI systems that learn like humans do: Now led by Dileep, our AGI division tackles the research and engineering challenges of building systems that exhibit these capabilities: how intelligent agents adapt continuously to changing environments, correctly attribute rewards to actions in scenarios with sparse feedback, and build hierarchical memory systems that enable efficient retrieval and generalization.
Dileep and his team will work closely with Doris, whose work has revealed some of the most detailed accounts of how neural activity produces perception to date. Together, they hope to create an iterative research program where neuroscience discoveries inform engineering approaches, and engineering challenges surface new neuroscience questions. Going forward, we hope to see others more tightly link basic neuroscience and applied AI work.
This work will be conducted in line with Astera’s broader commitment to open science. We believe progress on AGI is better served by distributed work across the field than by locking insights away.
The team this requires
We’re now building a team whose capabilities span deep theoretical investigation of biological intelligence, large-scale ML systems engineering, and experimental validation of novel architectures.
We’re actively looking for researchers and engineers with strong machine learning backgrounds and deep curiosity about neuroscience: people who want to investigate what’s missing from current approaches and build something better.
If this vision excites you — whether you’re a researcher, engineer, or someone who wants to work on foundational questions about intelligence — we want to hear from you.
There’s always a need for more ideas and talent in this area. If you have an interesting, underexplored angle you’d like to chase down, we’ve also recently opened a call for applications to the Neuroscience and Artificial Intelligence tracks of Astera’s residency program. Our residency is meant to support talented innovators seeding early-stage projects, especially those that might sit outside of what’s conventionally pursued. We’re building a community here that could be a great hub for this type of exploration. We hope you will consider applying.
Important science and technology development often falls through the cracks of public funding and private markets, i.e. work that may be high impact but risky, requires long timelines, or involves unpopular ideas. These areas are ripe for philanthropy. And as AI ushers civilization toward an event horizon, we need more people working on the hardest problems with many shots on goal.
Over the last five years at Astera, we’ve tested different approaches to funding and building ambitious technical work. We’ve explored a lot of directions to figure out where we think we can have the most impact. We’re now sharpening our focus on two areas: intelligence—both biological and artificial—and AI-enabled life sciences. Progress in either could help positively shape humanity’s future in critical ways.
Both areas benefit from more philanthropic support, as they involve open questions, unexplored territory, and long timelines. The right experiments aren’t always obvious, and success might look nothing like expected. We’ve also chosen them because we personally know them well. Jed is an engineer focused on neuroscience and intelligence foundations; Seemay is a biologist experimenting with how research gets done. We engage directly with technical details, which allows us to embrace more uncertainty.
Structure and flexibility for technical work
Creating an organizational structure that sustains this work over decades requires more than knowing where to focus. We’ve found the most effective technical efforts function like startups: flexible, nimble, guided by leaders with real authority to make technical calls.
Like start-ups, they also need to be able deploy resources in a much more flexible way than is typical of most philanthropy. In addition to giving out grants, we find that work—especially of the more opinionated type—benefits from a wide range of tactical strategies, including hiring, contracts, competitions, and for-profit investments.
Moving forward, we’re intentionally separating Astera’s foundation from the technical divisions it supports. The foundation handles shared operational and administrative infrastructure to enable technical teams that run semi-independently like start-ups. Each has a leader with deep expertise and CEO-like authority, supported by flexible, long-term capital and operational scaffolding through the foundation. These include:
Neuro & AGI divisions that explore how biological systems compute, how that relates to artificial systems, and what approaches might lead toward general intelligence. We think there’s a wider space of possible architectures than currently explored, and neuroscience offers crucial insights. This builds on work by our current researchers and fellows.
A life sciences division, where we’re rethinking how science gets done in the age of AI. Today’s scientific approaches were largely designed for a different era. AI has given new urgency to the need to reimagine our practices, motivating us to expand efforts around funding, structuring, and publishing approaches. We believe that the best way to innovate on this front is by iterating alongside active, ambitious research efforts. For instance, by embedding initiatives like The Diffuse Project with open science experimentation.
The right leaders
Our new start-up-like approach only works if there are the right leaders in place. We look for people comfortable with uncertainty, technical enough to engage directly, with a builder mentality to create what’s needed. Critically, we’ve sought out people whose primary experience is outside philanthropy from industry, startups, or research environments.
We’ve already been fortunate to attract such people. In the coming weeks, we’re excited to share about several exciting new folks who will be joining Astera to help lead new divisions in intelligence and life sciences. In parallel, we’re also refocusing the residency program to better prioritize people and ideas where we have long-term commitment and in-house expertise.
We’re still learning
Astera has always been an experiment in doing philanthropy differently. This structure is another iteration. We have strong convictions but expect to keep adapting.
We’re eager to connect with people and organizations thinking about new approaches to funding or doing science. Or if you’re working on similar problems in intelligence or life sciences, we’d like to hear from you.
More at astera.org, or reach out at info@astera.org.

The Astera Institute is excited to launch a major new neuroscience research effort led by Dr. Doris Tsao, who will be joining as Chief Scientist for Astera Neuro. We seek to understand one of the deepest mysteries of science: how the brain produces conscious experience, cognition, and intelligent behavior. Astera will support this effort with $600M+ over the next decade.
Doris has spent her career developing one of the most detailed accounts of how neural activity gives rise to perception through work on the neural code and circuitry underlying face and object recognition. This work shows how a complex visual percept, object identity, is represented by a principled geometric code. Her recent work explores a new computational framework for how symbols first arise in the brain through specialized circuits for object tracking.
What are we doing?
Across every moment of our lives, the brain transforms raw sensory input into a coherent world filled with objects, relationships, meanings, and a sense of self. Yet we still do not understand the fundamental computational principles the brain uses to construct this internal world. Uncovering these principles would transform both neuroscience and technology–revealing the mechanism responsible for generating conscious experience, and at the same time, providing a new framework for AGI.
At the heart of our new effort is the conviction that true understanding of the brain’s internal model means being able to manipulate it in a controlled way. Towards this goal, we are betting that the brain’s representational architecture is compositional, built from elemental units and a neural syntax for combining them. By identifying these fundamental units and the rules that create and link them, we can uncover the brain’s infinitely generative internal code. This, in turn, would provide a principled way to construct or modify internal representations, much as knowing the words and grammar of a language allows the creation of an unlimited range of sentences and meanings. Such capability would mark a profound advance in understanding.
The compositional framework remains a hypothesis, but pursuing it opens a path for fundamentally new kinds of experiments. The first step will be to measure neural activity through large-scale recordings across a rich variety of stimuli and behaviors, allowing us to characterize the underlying neural code. We will then attempt to write in hypothesized neural codes and thereby construct or alter internal representations according to proposed compositional rules. In this way, we can move neuroscience beyond passive observation and towards active, engineering-style tests of a model. Whether or not our hypothesis proves fully correct, this approach will accelerate our understanding of how the brain’s internal model is built.
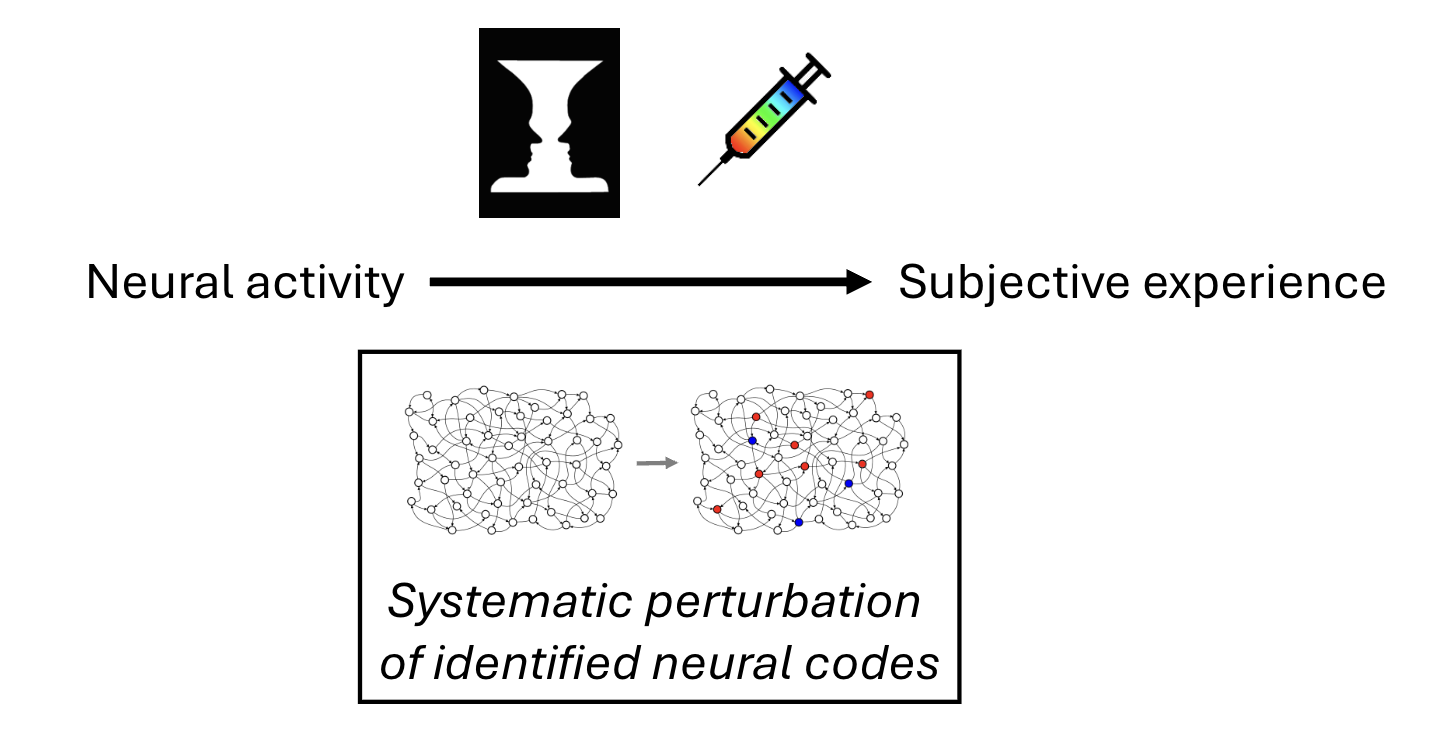
A field ready for a paradigm shift
The ability to precisely map and modify the brain’s internal model may sound like a lofty goal and indeed, for decades, progress in neuroscience was limited by technology. But that barrier has largely fallen, and we believe now is the right time for our moonshot. We now have the tools to interrogate the brain at unprecedented resolution and scale.
What is needed next is a coordinated engineering effort to fully harness these tools. Advances in large-scale neural recording, targeted stimulation, chronic high-density interfaces, and computational modeling have created a unique moment where a focused, non-clinical, scientifically driven program can push far beyond what academic labs or clinically oriented companies alone can achieve. We intend to fill this essential gap between traditional basic research and clinically driven neurotechnology.
Progress towards our goals opens major branches of independent inquiry:
- Inspiring new approaches to building and steering AI systems: Understanding the brain’s computational strategies—the architectural principles and representations—could reveal fundamentally different approaches to building AI systems that are orders of magnitude more efficient and naturally aligned with human cognition. Industry pursues only a narrow slice of what’s possible. We believe reverse-engineering the only generalized intelligence in existence could open up new pathways to general artificial intelligence.
- Deepening our fundamental understanding of biological intelligence and conscious experience: The brain is one of the universe’s wonders. What is the structure of neural activity required for a specific experience? What are the primitives of perception and thought? How does the brain represent itself? How do disruptions in the brain manifest as psychiatric and neurological conditions? We seek to develop a theory of conscious experience that successfully predicts the experiences that emerge when we write specific patterns to the brain.
- Opening pathways to revolutionary neural interventions: Today’s brain-machine interfaces work at the periphery, translating motor commands or delivering basic sensory inputs. But understanding deeper computational structures could enable interfaces that engage with the brain’s core representational system. This could have major therapeutic applications, for example, a visual prosthesis for the blind that restores vivid, naturalistic visual experience, not just pixelated sight.
Why Astera is pursuing this work
Since the founding of the Astera Institute in 2020, Obelisk, Astera’s AGI research program, has pursued the hypothesis that a better understanding of how intelligence arises in natural systems could reveal computational principles missing from current AI paradigms. The brain achieves flexible, general intelligence with roughly 20 watts of power. It constructs everything we experience—every object we see, every thought, every feeling—from patterns of electrical activity across ~100 billion neurons. It learns continuously from sparse data. It plans, imagines, and constructs a coherent model of the world. We don’t yet understand how.
Astera Neuro brings deep experimental neuroscience into direct dialogue with this work. We hope to create a tight iterative loop across teams where experimental findings shape AI architecture research, and computational questions drive new lines of neuroscientific inquiry.
We believe Doris has developed what may be the most detailed empirical account of how neural activity produces perception so far. The potential of her work requires long-term investment. We are excited to work with Doris to test her model and systematically explore how the brain constructs reality in direct collaboration with Obelisk engineers and researchers exploring alternative approaches to AGI. The iteration between these basic and applied research efforts will surface things neither could find separately.
Research will be shared exclusively outside traditional journals as a forcing function for developing faster, more open, and more useful outputs that represent the full scientific process. As we’ve seen with other efforts, we believe such an approach will enable greater alignment of scientific goals and values across the team. We will also be iterating on ways to make these outputs more compatible with AI-driven discovery.
Building the team
We are excited for the opportunity to build this moonshot. We have a chance to experiment with how science can be done by designing our team and approaches in a purposeful way. This work requires capabilities that don’t typically collaborate as part of a cohesive iterative circuit at an institutional scale: neuroscientists who can design experiments on complex natural behaviors, ML engineers who can build models from massive neural datasets, optical engineers working on holographic optogenetics and advanced imaging, systems builders who can create scalable experimental infrastructure, and metascience innovators dedicated to accelerating all aspects of this work.
Doris brings decades of foundational work on neural coding. For her next chapter with Astera, she is joined by an exceptional founding team (soon to be announced) whose contributions span large-scale reading and writing to neural circuits, clarifying the neural basis for cognition, and understanding brain function during naturalistic behavior.
We are now looking for a Chief Operating Officer who will work in direct partnership with Jed and Doris to transform their scientific vision into operational reality. They will be orchestrating collaboration across disciplines, building systems that support both rigor and speed, and helping create an organization capable of tackling problems at this scale.
What do standardized, low-cost space telescopes, ultra-high-performance bio-inspired materials, and fusion energy that costs under 1¢/kWh all have in common? For one, each of these domains holds incredible potential to further human flourishing. And secondly, each represents a new idea that will be pursued over the next year at our Emeryville, CA campus.
We’re delighted to introduce three new residents to our Residency Program — a program in which residents receive a salary, a budget of up to $2M for team and expenses, compute access, lab space, and an exceptional community of talented like-minded peers, mentors, and investors.
Read on to learn more about our three new ambitious entrepreneurs, along with a brief overview of their work. In the coming months, we’ll be sharing more detailed profiles of the residents and their projects.
If you’re interested in applying to be a future resident, you can reach us at residency@astera.org, or subscribe here to receive our next call for applications, coming in early 2026.

Aaron Tohuvavohu – Cosmic Frontier Labs
Dr. Aaron Tohuvavohu is a physicist, astronomer, and explorer designing the next generation of space telescopes. He has designed missions and experiments across the electromagnetic and multi-messenger spectrum, with expertise spanning black holes, relativistic explosions, UV and X-ray instrumentation, and space systems engineering. Most recently, he led an 11-month sprint from clean sheet to launch of the highest-performance UV detector in orbit, and drove major upgrades to NASA’s Swift Observatory, significantly expanding its scientific reach, impact, and efficiency.
Project description
Cosmic Frontier Labs is building a new class of scientific tools to accelerate discovery and exploration of the Universe. We are expanding humanity’s cosmic horizons by scaling up the number and capability of orbital observatories, bringing Hubble-quality to fleets of telescopes rather than single flagships. By redesigning precision instruments for manufacturability and iteration, the team is moving space astronomy from an era of scarcity to one of abundance, continuous innovation, and exponential discovery.
These telescopes will form a platform for science that evolves as quickly as the questions we ask. We will build the platform iteratively, to continuously integrate new detectors, optics, and algorithms on successive units. In this near future, exploring the cosmos won’t depend on waiting decades for the next great observatory, but on a living, growing constellation of instruments; each a window into the expanding frontier of human understanding.
Open roles: Contact info@cosmicfrontier.org if you’re interested in the mission and want to explore ways to contribute!

Damien Scott – 1cFE
Damien Scott is a technologist and founder. Homeschooled in Botswana and shaped by science fiction, his north star is to build energy systems that move humanity up the Kardashev scale toward post-scarcity. His first entrepreneurial venture was founding Marain, an electric and autonomous-vehicle simulation and optimization company that was acquired by General Motors in 2022. His career has spanned energy and mobility systems across startups and large companies, including the extreme engineering environment of Formula 1 at Williams F1. Beyond racing, he worked on a wide variety of initiatives, from adapting uranium-enrichment centrifuge concepts, to electromechanical flywheel energy storage, to hybrid hypercars and automated mining systems. He has a BSc in physics from the University of Sydney and an MS and MBA from Stanford University.
Project description
Everything humanity values depends on abundant, inexpensive energy. Most usable energy across the universe is fusion…with extra steps. The last decade has brought major public and private progress towards cutting out those steps, to directly generate electricity from fusion, and bring us closer to abundant, low-cost energy. The 1cFE initiative builds on this progress to set our ambitions higher: could the cost of fusion reach below-1¢/kWh LCOE within the next ten years? We map cost-first corridors to sub-cent power, integrating physics, engineering, and manufacturing. We will also publish open analyses, and test how emerging AI capabilities can radically improve and compress cycles across science, first-of-a-kind engineering, and deployment. Our outputs are intended to steer R&D, capital allocation, and policy toward the fastest corridors to sub-cent fusion energy, thereby pushing humanity up the Kardashev scale and upgrading our civilization.
Open roles: Theoretical Physicist and Systems Engineer

Tim McGee – Impossible Fibers
Tim McGee is a biologist and materials innovator developing new ways for proteins and composites to self-assemble into high-performance materials. Trained in Biomolecular Science and Engineering at UCSB, his mission is to translate biology into design and manufacturing. As an early pioneer of bio-inspired design at Biomimicry 3.8, IDEO, and later his own firm, LikoLab, he has worked with global teams on challenges ranging from advanced coatings for food, to novel textile manufacturing, to the biophilic design of urban environments. Most recently, McGee founded Impossible Fibers at Speculative Technologies, leading a DARPA-funded collaboration to predict fiber properties directly from amino acid sequences. His work integrates biology, design, and engineering to create new manufacturing capabilities where materials are assembled from the nanoscale to the macroscale.
Project description
The Impossible Fibers Lab is building a new manufacturing environment that enables proteins to self-assemble into exceptional materials; fibers and composites with electrical, optical, and mechanical properties beyond what’s achievable today. Existing fiber production systems were designed a century ago, and were made for cellulose and plastics, not for the complexity of proteins. McGee’s team combines microfluidics engineering, encapsulation chemistry, automated liquid handling and robotics, and novel spinning techniques to explore how protein composites form, align, and transform during fiber fabrication. The resulting structured dataset will map the relationships between molecular sequence, process conditions, and material outcomes, creating the foundation for predictive, bio-inspired materials design.
In the long term, Impossible Fibers seeks to make matter programmable, from quantum interactions to custom product-scale performance, laying the foundations for a new era of materials manufacturing.
—
Extending a warm welcome to our new residents, and stay tuned for a deeper dive into their work!