Dileep George is joining Astera as Head of AI, leading our AGI research division. Working alongside our Chief Scientist Doris Tsao, he and the team will explore novel, brain-inspired computational architectures to accelerate the development of safe, efficient and aligned AGI. Astera will continue to support this effort with over $1 billion in committed resources over the coming decade.
Dileep joins from Google DeepMind, where he worked on frontier AGI research on agents with memory, planning and structure learning. Throughout his career, Dileep has shown that drawing on the computational principles of biological intelligence opens up novel, high-impact pathways for AGI research. At Vicarious, he scaled algorithms for visual processing and reasoning, gaining worldwide attention for breaking text-based CAPTCHAs with human-like data efficiency. He also pioneered AI-powered robotics as a service for industrial applications. At Numenta, he co-developed Hierarchical Temporal Memory, the theoretical framework modeling how the neocortex learns and reasons.
Dileep joins Astera alongside Miguel Lázaro-Gredilla, previously a Research Scientist at Google DeepMind. As Research Lead, Miguel will spearhead the development of world models that utilize hierarchical latent variables for long-horizon planning and robust reasoning.

Neuro-inspired AGI research is underexplored relative to its potential
The overwhelming majority of AI research today pursues a dominant paradigm: scaling transformer architectures trained on massive datasets. This approach has produced remarkable results and will likely continue to do so, but concentration around any single research direction leaves promising alternatives underexplored.
The principles of biological intelligence likely offer novel approaches to AI engineering at scale that aren’t captured in existing research paradigms. This could help address two sets of challenges that remain on the path to AGI:
1. Current AI systems lack fundamental capabilities that biological intelligence demonstrates. They can’t handle long-range planning that requires maintaining coherent goals across complex action sequences, or learn continuously from experience the way humans do. Massive datasets are still required for tasks where humans need only a handful of examples, and they continue to fail to generalize robustly to situations that differ meaningfully from their training data.
2. The safety and alignment challenges posed by current architectures remain unsolved, even as we continue to scale them. We don’t yet know how to build systems whose goals stay aligned with human values as circumstances change in ways they weren’t trained for. We can’t reliably interpret why models make the decisions they do, which makes it difficult to predict or prevent failures.
Commercial investments currently concentrate on scaling transformers, which risks trapping the field in local minima: optimizing a single approach while leaving vast parts of the solution space unexplored. Biological intelligence offers computational principles that current architectures don’t capture, opening pathways to systems that are more efficient and more naturally aligned with how humans think and perceive.
Bridging neuroscience and AI engineering
Efforts to map biological intelligence — how the brain constructs perception, cognition, and intelligence itself — remain disconnected from the engineering of AI systems. Neuroscience and AI research proceed largely in parallel with limited integration.
Providing decade-scale commitment and computational resources, Astera is running two research programs in tight integration:
- Decoding the brain’s computational architecture: Led by Doris Tsao, Chief Scientist for Astera Neuro, our Neuro division is working to decode the fundamental mechanisms through which the brain constructs intelligence. These capabilities represent some of the hardest unsolved problems in AI, and the brain solves them with remarkable efficiency.
- Building AI systems that learn like humans do: Now led by Dileep, our AGI division tackles the research and engineering challenges of building systems that exhibit these capabilities: how intelligent agents adapt continuously to changing environments, correctly attribute rewards to actions in scenarios with sparse feedback, and build hierarchical memory systems that enable efficient retrieval and generalization.
Dileep and his team will work closely with Doris, whose work has revealed some of the most detailed accounts of how neural activity produces perception to date. Together, they hope to create an iterative research program where neuroscience discoveries inform engineering approaches, and engineering challenges surface new neuroscience questions. Going forward, we hope to see others more tightly link basic neuroscience and applied AI work.
This work will be conducted in line with Astera’s broader commitment to open science. We believe progress on AGI is better served by distributed work across the field than by locking insights away.
The team this requires
We’re now building a team whose capabilities span deep theoretical investigation of biological intelligence, large-scale ML systems engineering, and experimental validation of novel architectures.
We’re actively looking for researchers and engineers with strong machine learning backgrounds and deep curiosity about neuroscience: people who want to investigate what’s missing from current approaches and build something better.
If this vision excites you — whether you’re a researcher, engineer, or someone who wants to work on foundational questions about intelligence — we want to hear from you.
There’s always a need for more ideas and talent in this area. If you have an interesting, underexplored angle you’d like to chase down, we’ve also recently opened a call for applications to the Neuroscience and Artificial Intelligence tracks of Astera’s residency program. Our residency is meant to support talented innovators seeding early-stage projects, especially those that might sit outside of what’s conventionally pursued. We’re building a community here that could be a great hub for this type of exploration. We hope you will consider applying.
Important science and technology development often falls through the cracks of public funding and private markets, i.e. work that may be high impact but risky, requires long timelines, or involves unpopular ideas. These areas are ripe for philanthropy. And as AI ushers civilization toward an event horizon, we need more people working on the hardest problems with many shots on goal.
Over the last five years at Astera, we’ve tested different approaches to funding and building ambitious technical work. We’ve explored a lot of directions to figure out where we think we can have the most impact. We’re now sharpening our focus on two areas: intelligence—both biological and artificial—and AI-enabled life sciences. Progress in either could help positively shape humanity’s future in critical ways.
Both areas benefit from more philanthropic support, as they involve open questions, unexplored territory, and long timelines. The right experiments aren’t always obvious, and success might look nothing like expected. We’ve also chosen them because we personally know them well. Jed is an engineer focused on neuroscience and intelligence foundations; Seemay is a biologist experimenting with how research gets done. We engage directly with technical details, which allows us to embrace more uncertainty.
Structure and flexibility for technical work
Creating an organizational structure that sustains this work over decades requires more than knowing where to focus. We’ve found the most effective technical efforts function like startups: flexible, nimble, guided by leaders with real authority to make technical calls.
Like start-ups, they also need to be able deploy resources in a much more flexible way than is typical of most philanthropy. In addition to giving out grants, we find that work—especially of the more opinionated type—benefits from a wide range of tactical strategies, including hiring, contracts, competitions, and for-profit investments.
Moving forward, we’re intentionally separating Astera’s foundation from the technical divisions it supports. The foundation handles shared operational and administrative infrastructure to enable technical teams that run semi-independently like start-ups. Each has a leader with deep expertise and CEO-like authority, supported by flexible, long-term capital and operational scaffolding through the foundation. These include:
Neuro & AGI divisions that explore how biological systems compute, how that relates to artificial systems, and what approaches might lead toward general intelligence. We think there’s a wider space of possible architectures than currently explored, and neuroscience offers crucial insights. This builds on work by our current researchers and fellows.
A life sciences division, where we’re rethinking how science gets done in the age of AI. Today’s scientific approaches were largely designed for a different era. AI has given new urgency to the need to reimagine our practices, motivating us to expand efforts around funding, structuring, and publishing approaches. We believe that the best way to innovate on this front is by iterating alongside active, ambitious research efforts. For instance, by embedding initiatives like The Diffuse Project with open science experimentation.
The right leaders
Our new start-up-like approach only works if there are the right leaders in place. We look for people comfortable with uncertainty, technical enough to engage directly, with a builder mentality to create what’s needed. Critically, we’ve sought out people whose primary experience is outside philanthropy from industry, startups, or research environments.
We’ve already been fortunate to attract such people. In the coming weeks, we’re excited to share about several exciting new folks who will be joining Astera to help lead new divisions in intelligence and life sciences. In parallel, we’re also refocusing the residency program to better prioritize people and ideas where we have long-term commitment and in-house expertise.
We’re still learning
Astera has always been an experiment in doing philanthropy differently. This structure is another iteration. We have strong convictions but expect to keep adapting.
We’re eager to connect with people and organizations thinking about new approaches to funding or doing science. Or if you’re working on similar problems in intelligence or life sciences, we’d like to hear from you.
More at astera.org, or reach out at info@astera.org.
What do standardized, low-cost space telescopes, ultra-high-performance bio-inspired materials, and fusion energy that costs under 1¢/kWh all have in common? For one, each of these domains holds incredible potential to further human flourishing. And secondly, each represents a new idea that will be pursued over the next year at our Emeryville, CA campus.
We’re delighted to introduce three new residents to our Residency Program — a program in which residents receive a salary, a budget of up to $2M for team and expenses, compute access, lab space, and an exceptional community of talented like-minded peers, mentors, and investors.
Read on to learn more about our three new ambitious entrepreneurs, along with a brief overview of their work. In the coming months, we’ll be sharing more detailed profiles of the residents and their projects.
If you’re interested in applying to be a future resident, you can reach us at residency@astera.org, or subscribe here to receive our next call for applications, coming in early 2026.

Aaron Tohuvavohu – Cosmic Frontier Labs
Dr. Aaron Tohuvavohu is a physicist, astronomer, and explorer designing the next generation of space telescopes. He has designed missions and experiments across the electromagnetic and multi-messenger spectrum, with expertise spanning black holes, relativistic explosions, UV and X-ray instrumentation, and space systems engineering. Most recently, he led an 11-month sprint from clean sheet to launch of the highest-performance UV detector in orbit, and drove major upgrades to NASA’s Swift Observatory, significantly expanding its scientific reach, impact, and efficiency.
Project description
Cosmic Frontier Labs is building a new class of scientific tools to accelerate discovery and exploration of the Universe. We are expanding humanity’s cosmic horizons by scaling up the number and capability of orbital observatories, bringing Hubble-quality to fleets of telescopes rather than single flagships. By redesigning precision instruments for manufacturability and iteration, the team is moving space astronomy from an era of scarcity to one of abundance, continuous innovation, and exponential discovery.
These telescopes will form a platform for science that evolves as quickly as the questions we ask. We will build the platform iteratively, to continuously integrate new detectors, optics, and algorithms on successive units. In this near future, exploring the cosmos won’t depend on waiting decades for the next great observatory, but on a living, growing constellation of instruments; each a window into the expanding frontier of human understanding.
Open roles: Contact info@cosmicfrontier.org if you’re interested in the mission and want to explore ways to contribute!

Damien Scott – 1cFE
Damien Scott is a technologist and founder. Homeschooled in Botswana and shaped by science fiction, his north star is to build energy systems that move humanity up the Kardashev scale toward post-scarcity. His first entrepreneurial venture was founding Marain, an electric and autonomous-vehicle simulation and optimization company that was acquired by General Motors in 2022. His career has spanned energy and mobility systems across startups and large companies, including the extreme engineering environment of Formula 1 at Williams F1. Beyond racing, he worked on a wide variety of initiatives, from adapting uranium-enrichment centrifuge concepts, to electromechanical flywheel energy storage, to hybrid hypercars and automated mining systems. He has a BSc in physics from the University of Sydney and an MS and MBA from Stanford University.
Project description
Everything humanity values depends on abundant, inexpensive energy. Most usable energy across the universe is fusion…with extra steps. The last decade has brought major public and private progress towards cutting out those steps, to directly generate electricity from fusion, and bring us closer to abundant, low-cost energy. The 1cFE initiative builds on this progress to set our ambitions higher: could the cost of fusion reach below-1¢/kWh LCOE within the next ten years? We map cost-first corridors to sub-cent power, integrating physics, engineering, and manufacturing. We will also publish open analyses, and test how emerging AI capabilities can radically improve and compress cycles across science, first-of-a-kind engineering, and deployment. Our outputs are intended to steer R&D, capital allocation, and policy toward the fastest corridors to sub-cent fusion energy, thereby pushing humanity up the Kardashev scale and upgrading our civilization.
Open roles: Theoretical Physicist and Systems Engineer

Tim McGee – Impossible Fibers
Tim McGee is a biologist and materials innovator developing new ways for proteins and composites to self-assemble into high-performance materials. Trained in Biomolecular Science and Engineering at UCSB, his mission is to translate biology into design and manufacturing. As an early pioneer of bio-inspired design at Biomimicry 3.8, IDEO, and later his own firm, LikoLab, he has worked with global teams on challenges ranging from advanced coatings for food, to novel textile manufacturing, to the biophilic design of urban environments. Most recently, McGee founded Impossible Fibers at Speculative Technologies, leading a DARPA-funded collaboration to predict fiber properties directly from amino acid sequences. His work integrates biology, design, and engineering to create new manufacturing capabilities where materials are assembled from the nanoscale to the macroscale.
Project description
The Impossible Fibers Lab is building a new manufacturing environment that enables proteins to self-assemble into exceptional materials; fibers and composites with electrical, optical, and mechanical properties beyond what’s achievable today. Existing fiber production systems were designed a century ago, and were made for cellulose and plastics, not for the complexity of proteins. McGee’s team combines microfluidics engineering, encapsulation chemistry, automated liquid handling and robotics, and novel spinning techniques to explore how protein composites form, align, and transform during fiber fabrication. The resulting structured dataset will map the relationships between molecular sequence, process conditions, and material outcomes, creating the foundation for predictive, bio-inspired materials design.
In the long term, Impossible Fibers seeks to make matter programmable, from quantum interactions to custom product-scale performance, laying the foundations for a new era of materials manufacturing.
—
Extending a warm welcome to our new residents, and stay tuned for a deeper dive into their work!
We’re moving into an age in which agents are our partners across all aspects of science. Machines will systematically process data, spot patterns, propose experiments, and even generate hypotheses across more and more of our work. I’m excited for how this will accelerate science.
A technological shift of this magnitude requires a similarly big shift in what we study and how we go about it. For one, there should be significantly more emphasis on what data is important to generate and how we build, share, and scale datasets. For another, there should be much more emphasis on funding system architecture that best enables systematic AI-driven discovery, as opposed to primarily funding individual labs to expand datasets.
Today, I’m happy to announce a new $5M funding initiative in structural biology that will experiment with how we make this shift.
The role of scientists in science
Humans remain essential in science. This is a critical moment to stake out where we can most uniquely contribute. What can’t AI solve yet? And for the things it can, how can we leverage its capabilities to do even more creative, generative exploration beyond that radius?
Machines excel at synthesizing large amounts of information through systematic data processing, pattern recognition, and probability calculations. We should replace ourselves in those types of analyses where possible. It’s an uncomfortable, but necessary transition.
There’s still plenty of upstream and downstream work that only we can do:
- Downstream: ML predictions are hypotheses, not conclusions. We must test them through research and reuse, closing the loop to validate and improve predictions.
- Upstream: Machines work with the data we give them; the nature and design of this data sets the ceiling for what’s possible to predict. We decide what questions to ask and how to architect the systems to answer them.
This piece focuses on the upstream. Too many research proposals focus on generating more data without asking how those expensive exercises will get us somewhere worthwhile. Many brute-force scaling efforts will hit diminishing returns unless we first rethink the kinds of data and data systems we need. This is where human ingenuity will matter most.
The next PDB is the PDB
We need to work smarter, not just harder. As a structural biologist, I’ll give an example close to my heart. And one I’m funding next.
A common trope in funding circles is “What’s the next Protein Data Bank (PDB)?” The question is asked as if structural biology were “done” post-AlphaFold. However, one next big challenge is the PDB; it’s in moving from static protein structures to predicting how they move.
Since form informs function, we use protein structures as clues for what proteins might do in cells. But proteins inherently work through motion: traveling, binding, catalyzing, breathing, and changing conformations. Unlocking protein dynamics would be a giant leap toward uncovering more protein function. This helps us better understand, engineer, and manipulate biology. Biotech companies are already attempting to leverage local data or simulations about protein dynamics for drug modeling.
So one of the “next PDBs” is the PDB itself. It’s not just a remake; it’s PDB 2.0, wherein we can transition from static snapshots to movies. PDB 2.0 can bring protein structures to life.
To get there, we need to think carefully about what conditions are required for such a breakthrough. PDB 1.0’s success depended on being large and standardized, with open data norms. But it also hinged on two other major elements:
- Getting the right slice of information The PDB didn’t contain all protein structures. But it had enough variation in sequences and folds to reveal key design principles. Data was structured for computation (e.g., multiple sequence alignments) to enable breakthroughs. Today, we know more about ML needs, so we can be intentional about focusing our efforts on the data that is most information-rich.
- Scaling through embedded practice The PDB scaled because crystallography naturally produced standardized data as a byproduct of routine work across methods, hardware, file formats, and infrastructure. This reduced marginal costs as the practice spread. It’s very different from a brute-force approach to data generation, where costs keep rising and the volume of data increases.
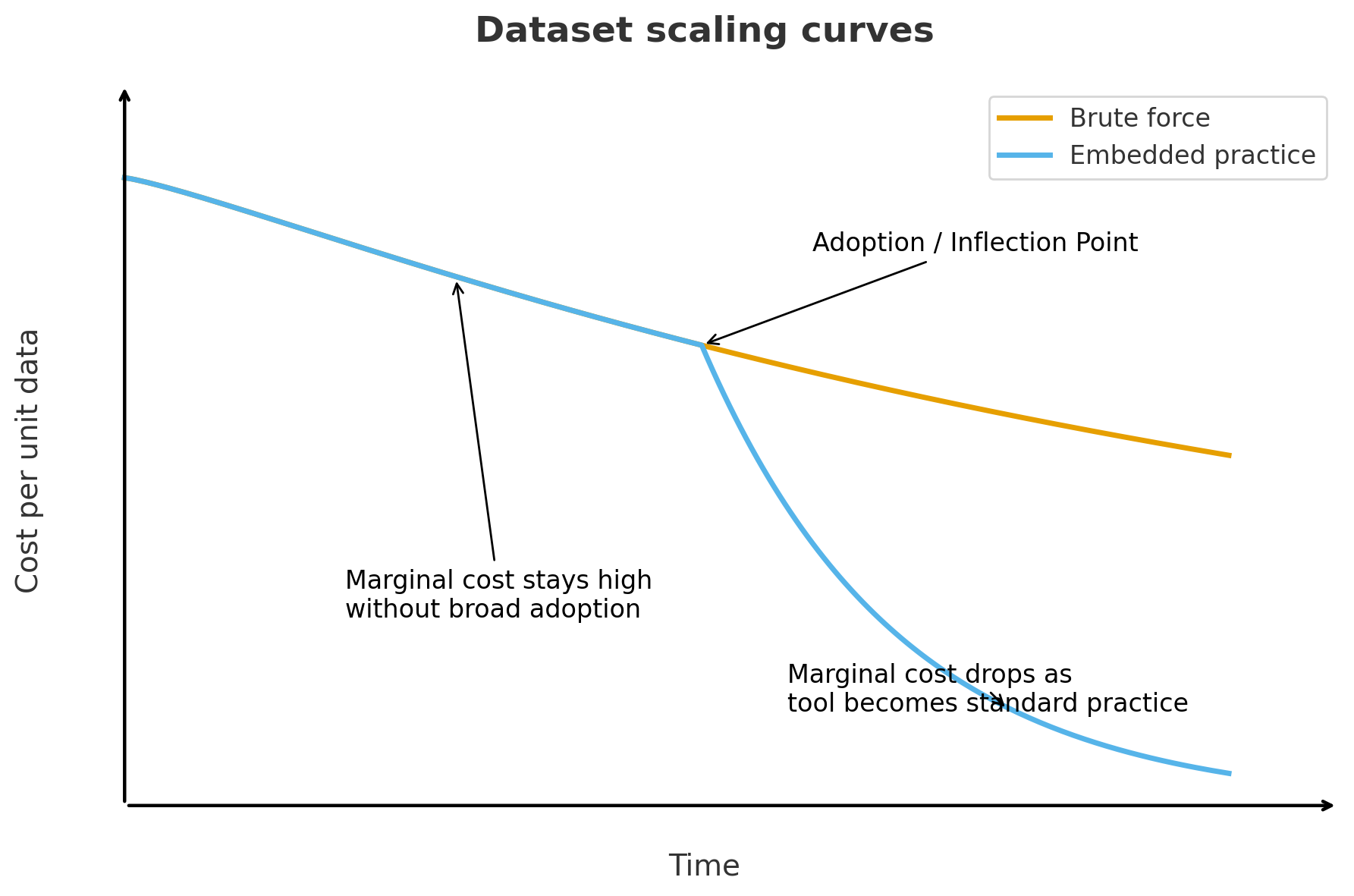
Finding the right information and embedding it in practice go hand in hand: the right “plumbing” motivates and enables the scientific community to capture valuable data.
We should challenge ourselves to be more cost-effective with PDB 2.0, now that we know more about what we are working towards. We also have machines to help us run quick calculations on what data is most information-dense and therefore most valuable. Instead of taking fifty years and costing tens of billions of dollars, could PDB 2.0 be faster and more efficient?
Principles in practice: introducing The Diffuse Project
With a $5M seed for The Diffuse Project from Astera, work will be coordinated across several universities (UCSF, Vanderbilt, Cornell), scientists associated with national labs and light sources (Los Alamos, Lawrence Berkeley, CHESS), and a team within Astera Institute. Our goal: redesign multiple components of the X-ray crystallography process to capture oft-discarded data on protein conformations.
Traditional crystallography focuses on Bragg scattering, the bright spots that represent the averaged conformation in a protein crystal. Other protein conformations in a crystal produce a more distributed signal — diffuse scattering — which is usually ignored due to its inherent complexity. But today, we have more tools to deal with the messy heterogeneity of diffuse scattering than ever before. Our technical aim is to transform diffuse scattering into a usable signal for hierarchical models of conformational ensembles. I’m excited by how current technologies allow us to better embrace biological complexity in this way.
In close collaboration with experts across the crystallography workflow, we’ve devised a strategy to test whether diffuse scattering could become mainstream practice in structural biology. Our parallel mission is to make the workflow useful, easy, and affordable for anyone studying protein function.
Our team is committed to radical open science by releasing data quickly and sharing progress entirely outside traditional journals — and there have already been many benefits. It has made our brainstorming and collaboration processes much more ambitious and fun. It’s freed us up to focus on outputs that are most useful and representative of our process.
An exciting aspect of the team’s open approach is the chance to experiment in real-time with what scientific publishing could look like in the future. Our open science team is collaborating with our researchers to figure out how they quickly share outputs that are most useful and most representative of our process. As AI becomes more central, our publishing will become more data-centric as well. This is an invaluable opportunity to iterate on this alongside active science to solve real problems on the ground.
We’ve only been in operation for about a month, and we already have data and results to share! You can follow all of this work on The Diffuse Project website.
Utility is the north star
Without journal constraints, we can think more clearly about what will make our science as impactful, accelerated, and rigorous as possible. We keep coming back to the mantra: utility is the north star.
What might high-utility success look like? Our answers span different time horizons, but we strive to be concrete. Here are some examples (which will likely evolve as we go):
- Adoption of diffuse scattering by experts outside the initiative
- Adoption of diffuse scattering by non-experts
- Integration of other modalities with a growing X-ray diffuse scattering dataset
- ML models for protein motion trained on diffuse scattering data
- Biotech start-ups founded from these models
- New therapeutics on the market developed from these models
The diffuse scattering work could take up 7–10 years to reach a scaling inflection point. That’s longer than most projects, but shorter than the time required for the original PDB to scale to a size that enabled AlphaFold. I’m optimistic that we could speed this up if The Diffuse Project truly succeeds in enabling the broader community. It’s a challenge that our team is excited to take on.
A note for funders
Funders, this is the time to flip the script on what science we support. We must move from primarily funding individuals to funding coordinated efforts that “lift all boats” in agent-led discovery systems.
Effective data systems will be a bottleneck for transformational ML. Systems have interdependent parts; if you don’t redesign multiple components at once, you risk getting stuck at a local maximum, due to dependencies between components. This is a well known principle in evolution and engineering. But we’re not great at applying this scientific framework to our own science. We need funding mechanisms that enable sustained, coordinated design sprints across interconnected entities with different areas of expertise.
This kind of systems-level innovation is risky for individual researchers. Not only does it require grappling with the unknown, it also requires grappling with many unknown pieces at once. Any proposal for a project like this would be disingenuous if it provided a super specific roadmap with a high degree of certainty.
Instead, funders need to redefine what success means so that researchers can embrace risk. Namely, teams should prioritize learning and sharing, even about their failures, which can often be informative. The goal can’t be to “win.” It needs to be to learn. The learning process is dynamic (just like proteins!) and we should fund and publish research with that in mind.
Iterating on data systems is also operationally risky. It requires proper infrastructure, engineering, compute access, and ML collaborations. We’re experimenting with unique ways to get this done without creating more bureaucracy or coordination overhead. Astera is providing compute access through Voltage Park and hiring a team for much of the computational and modeling work. This is another avenue by which funders can create an outsized impact through their support.
And at a minimum, we must insist on open science and open data practices. Otherwise, we risk limiting reuse, rigor, and impact. It’s the greatest insurance funders have for a return on their public good investment. Based on my own experiences, I’m very optimistic that we can hold the line on this without sacrificing talent. With the open science requirement, I’ve been able to quickly filter through to some of the smartest scientists, with the most abundant mindsets, with whom to go after big problems. The Diffuse Project’s team is awesome. I could not be more thrilled about the stellar set of scientists leading the research.
A first step towards the future
The Diffuse Project is not an outlier. It’s one example of the broader shift we need to make towards a data-centric future of discovery.
This shift will allow us scientists to work smarter. As machine learning systems become more prominent in hypothesis generation, simulation, and interpretation, the role of scientists will not disappear — it will evolve. Our ability to be creative about what data we generate, how we go about it, and what it enables, will become an increasingly central part of how we contribute to discovery.
This is not a loss. It’s an opportunity. It’s a chance — for both scientists and funders — to reclaim the architectural layer of science as a thoughtful, creative, and essential realm of experimentation and discovery. And it’s a place where human judgment still matters — perhaps more than ever.
If you’re working on something that could benefit from this kind of innovation, I’d love to see it published openly so I can follow and learn through open discourse. In the spirit of open science, I generally prefer not to respond to private emails or DMs. I would love to see open science publishing in effect at the ideation stage too.