
Interpretability is one of the biggest open questions in artificial intelligence. In other words, what’s going on inside these models?
Adam Shai and Paul Riechers are the co-founders of Simplex, a research organization and Astera grantee, focused on unpacking this question. They’re working to understand how AI systems represent the world — a critical component of AI safety with major societal implications.
We sat down with them for a conversation on internal mental structures in AI systems, belief-state geometries, what we can learn about intelligence at large, and why this all urgently matters.
How did you both decide to leave academic tracks to start Simplex?
Adam: My background was in experimental neuroscience. I spent over a decade in academia — during my postdoc, I was training rats to perform tasks, recording their neural activity, and trying to reverse-engineer how their brain neural activity leads to intelligent behavior. I thought I had some handle on how intelligence works.
During that time, ChatGPT came out. I was stunned at its abilities. I started digging into the transformer architecture, the underlying technology that powers ChatGPT, and I was even more shocked. The transformer architecture didn’t intuitively tell a story about its behavior.
I realized two things at that time. The first was unsettling. I’d thought of myself as a neuroscientist with a pretty good intuition for the mechanistic underpinnings of intelligence. But that intuition seemed to be completely incorrect here.
The second was even scarier. What are the societal implications for having this kind of intelligence at scale? The social need to understand these systems, and to understand intelligence more broadly, is more important than it’s ever been before. At the same time, there’s also this new opportunity to understand intelligence, not just for artificial systems, but maybe even for humans — to really learn more about our own cognition.
Paul: I came from a background in theoretical physics, thinking about the fundamental role of information in quantum mechanics and thermodynamics, with a recurring theme of predicting the future from the past — how to do that as well as possible. That’s traditionally a core part of physics — your equations of motion help you predict how the stars move, for example. But it also gets into chaos theory, where you have very few details available to predict a chaotic, complex world. And you quickly get to the ultimate limits of predictability and inference.
At the time, this had nothing to do with neural nets and I hadn’t paid much attention to them — they work on predictions of tokens, or chunks of words — but they seemed unprincipled compared to the beautiful theory work I was doing in physics. But then they started working — and not just working, but working really well. To the point where I started feeling uneasy about the future societal implications.
And given my background in prediction, I then started wondering what it might look like to apply the components of a principled mathematical framework to what these neural networks are doing. What are their internal representations? What emergent behaviors can we anticipate? I linked up with Adam and we tried the smallest possible thing we could. And it worked better than we could have hoped for.
That’s what grew into Simplex — we realized there wasn’t really a space for this yet, a program to solve interpretability all the way, and there’s a lot to build on. Our mission at Simplex is to develop a principled science of intelligence, to help make advanced AI systems compatible with humanity. It’s been a really fun collaboration and it’s leading us to a better understanding of how AI models are working internally, which then gives insight into what the heck we’re building as AI systems scale. We’re optimistic these insights can help create more options and guide the development of AGI towards better outcomes for humanity.
Thanks for reading Human Readable! Subscribe to receive news and updates from Astera Institute.
You’ve described AI models not as engineered systems, but as ‘grown’ ones…what do you mean by that?
Adam: Yeah, I think this is an under-appreciated aspect of this new technology. Most people assume they’re engineered programs. But they’re not like other software programs — they’re more like grown systems. Engineers set up the context and rules for growing, and then press play on the growing process. What they grow into and the path of their development isn’t engineered or controlled.
And so we’ve ended up with these systems that are incredibly powerful. They are writing, deploying, and debugging code, solving complex mathematical problems at near-human expert levels, and really peering over the edge of what humans can do. This isn’t a future scenario, that’s where we are right now. But we have very little idea of how these systems work internally. And that’s a problem — a lot of safety issues come from this unknown relationship between the behaviors of these systems and their internal processing.
Paul: For example, AI systems are increasingly showing signs of deception, especially when under safety evaluation. Some actively evade safeguards, while others generate plausible explanations that don’t match their true reasoning. These mismatches between external behavior and internal thought process of the AI highlight the need to understand the geometry and evolution of internal activations — without it, we’re largely blind to the system’s intentions.
So how do you go about studying that internal structure?
Paul: We’ve come up with a framework that started from a part of physics called computational mechanics — basically exploring the fundamental limits of learning and prediction by asking what features of the past are actually useful in predicting the future. And then we leveraged this structural part, which looks at the geometric relationship between these different features of the past.
Adam: We discovered that AI models organize information in consistent patterns, like a mental map consisting of specific types of shapes and structures. We call these patterns belief-state geometries, because fundamentally they are the AI model’s internal representation of what’s going on in the world. These patterns often have repeated structure at different scales, leading to intricate fractals. For instance, when we studied a transformer learning simple patterns, we found it creates a fractal structure that looks like a Sierpinski triangle — where each point represents a different belief about the probabilities of all possible futures. As the AI reads more text, it moves through this geometric space, updating its beliefs in mathematically precise ways that our theory predicted. Now that we have this framing, we can start to anticipate those structures. We can start to predict where in the network to look for them, and test whether our theories hold and we can refine them. It’s a huge shift from just poking around and hoping something interpretable falls out.
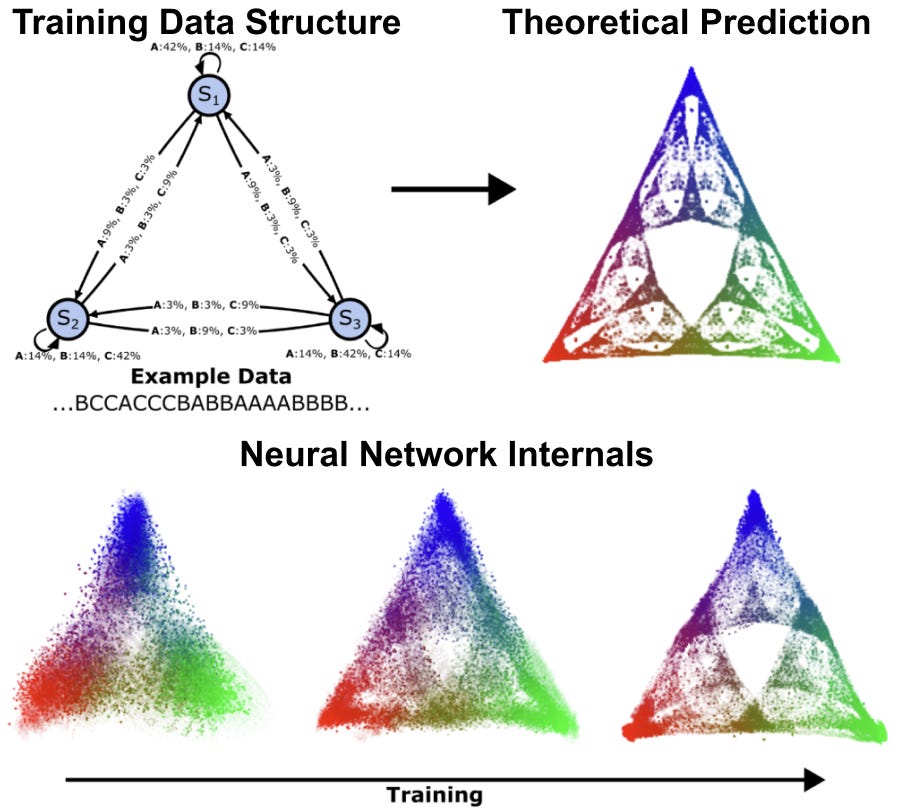
How does this differ from what others in the field are doing?
Adam: There’s a field of research called interpretability, which is trying to understand how the internals of AI systems carry out their behavior. It is very similar to the type of neuroscience I used to do, but applied to AI systems instead of to biological brains. There’s been an enormous amount of progress over the last few years, and a lot of interest because of the growth of LLMs. In many ways interpretability has even been able to surpass the progress in neuroscience.
However, the approach is often highly empirical. Despite all the progress, the field is often left wondering to what extent the findings apply to other situations that weren’t tested, or if their methods are really robust, or how to make sense of their findings. In a lot of ways, we still don’t really know what the thing we are looking for is, exactly. What does it look like to understand a system of interacting parts (whether they be biological or artificial neurons) whose collective activity brings about interesting cognitive behavior? What’s the type signature of that understanding?
Paul: What’s missing is a theoretical framework to guide empirical approaches. Our unique advantage is that, by taking a step back and really thinking about the nature of computation in these trained systems, we can anticipate the relationship between the internal structure and behaviors of AI systems. One of the most important points of this framework is that it is both rigorous and also amenable to actual experiments. We aren’t doing theory for theory’s sake. The point is to understand the reality of these systems. So it’s this feedback loop between theory and experiment that allows us to make foundational progress that we can trust and build on in a way that’s different from most other players in the field.
How might this type of geometric relationship between features of the past differ across sensory modalities — language, images, sounds, etc.? Is there a difference between how it works in humans and AI systems?
Paul: This is an area we’re really interested in exploring more. There’s some evidence that suggests that neural networks trained on different modalities converge on similar geometric representations of the world. It seems to be that no matter which modalities an intelligent system uses to interact with the world, it’s trying to reconstruct the whole thing.
It raises some fascinating questions — to what extent are different modalities and even different intelligences converging on a shared sense of understanding? Is there a unique answer to what it’s like to be intelligent? And if so, maybe that’s useful for increasing the bandwidth of communication among different intelligent beings? And if not — if each intelligent thing understands the world in a valid but incompatible way — that’s maybe not great for hopes of us being able to come to a shared understanding and aligned goals? So that’s one thing we’re very interested in as we learn how models represent the world.
Adam: I think there’s also a really interesting opportunity to understand ourselves better. It opens up this entire new field of access to understand intelligence. If you’re a neuroscientist, you no longer have to decide between studying a human brain and having very low access, or studying a rat and having more access at the expense of cognitive behavior. With neural networks, you can look at everything.
We can even potentially engineer neural networks to whatever level of complexity, whatever kind of data, and whatever kind of behavior we want to study, even at a level that exceeds human performance. And it opens up this new, really fast feedback loop between theory and experiment — it’s an unprecedented opportunity to understand intelligence in a very general sense.
Given your work is really about understanding intelligence more broadly, beyond just AI systems, where do you hope it will lead?
Adam: Previously, there’s been no framework that gives us any kind of foothold to talk about this relationship between internal structure and outward behavior. We’re trying to build this kind of principled framework for how to think about these questions. It could be applied to LLMs in order to understand them and make them safer. But the general framework also has the promise of being applicable to other systems where we’re trying to understand the relationship between the internal structure and outward behavior. And those other systems could be biological brains.
Paul: Part of the value we’re providing is also a shared understanding, or ground truth for how these systems work. Today, people have different opinions about what these systems are — some maintain that the current AI paradigm will fall short of AGI or superhuman intelligence, while a growing contingent finds it obvious that you can bootstrap a minimal amount of intelligence to become superhuman across the board. More concerning is that informed technologists disagree about whether ASI (artificial superintelligence) will most likely lead to human extinction or flourishing. Even among experts, people really talk past each other. AI safety may or may not be solvable. Part of our work is to establish a scientific foundation for coming to a consensus on that, and identifying paths forward.
I’m hopeful that we can elevate the conversation by creating a shared understanding of what the science says, so it’s no longer doomers and optimists, but rather people working together to figure out the implications of what we’re building, and how we steer towards the kind of future we want. It’s a lofty goal but we think it’s possible. As we continue to build our understanding of structures in our own networks, we’ll hopefully be able to leverage that for a societal conversation for what it is we want to be building towards.
Learn more about Simplex’s insights and follow their technical progress here.

What does it take to make — and keep — a planet habitable?
For over 50 years, humans have explored space, seeking new homes for life. Life on Mars is the stuff of great science fiction. And the work of actually creating sustainable habitats and ecosystems beyond Earth has, by extension, been a far-flung future. Now, that may be changing.
Edwin Kite is a planetary scientist and current resident at Astera who, together with his team and collaborators, is working on defining a contemporary Mars terraforming research agenda. We spoke with him about what it would take to warm Mars up enough for life to thrive, how open source tools and datasets help research communities build towards the future, and what drives a scientist to investigate how people might create ecosystems beyond Earth.
You’ve been working on Mars science for years. Why this planet?
The biggest unanswered question in Earth science is how and why our planet stayed habitable for life.
For example, for nine-tenths of Earth history, our planet has been uninhabitable for humans: we don’t know why oxygen levels rose.
These are especially interesting questions when you consider that Mars was once habitable, but lost its ability to sustain life. Mars holds a record of that environmental catastrophe, and may hold traces of life that established itself there before that natural disaster. We are in a golden age of Mars science today, with two plutonium-powered rovers on the surface and an international fleet of spacecraft in orbit. We can deeply explore the planet for signs of this record and seek answers to our questions about what happened. It’s a great time to be doing Mars science.
The biggest unanswered question in Earth science is how and why our planet stayed habitable for life.
Understanding what made and what ended Mars’s early habitability can also help us better understand Earth’s history of life and explore the possibility of re-making Mars habitable. Mars has plenty of water and carbon, and its surface receives about as much sunlight as does all of Earth’s land. Sunlight powers almost all of our biosphere, so it’s tantalizing to think of what kind of biosphere sunlight might support in the future on Mars. It’s by coevolution with photosynthetic life that people built cities.
Our ancestors were, in Darwin’s words, hairy forest-dwellers. They moved outwards and built tools like spacesuits and sealskin coats to allow human life in the face of once-unimaginable hazards, like hard vacuum and winter snow. But this approach can only take us so far. Throughout time, space has been forbidding to life, with radiation, micrometeoroids, and cold. If we are going to have an adventure that’s endless, we’ll need to adapt the environment to ourselves. I don’t know how we’ll do this, but the bigger rocky and icy worlds of our solar system seem like a logical place to start. Many are rich in life-essential-volatile elements, all can offer radiation protection, and all have enough gravity to hold onto a stable atmosphere.
What’s the scope of your current project at Astera, focused on terraforming?
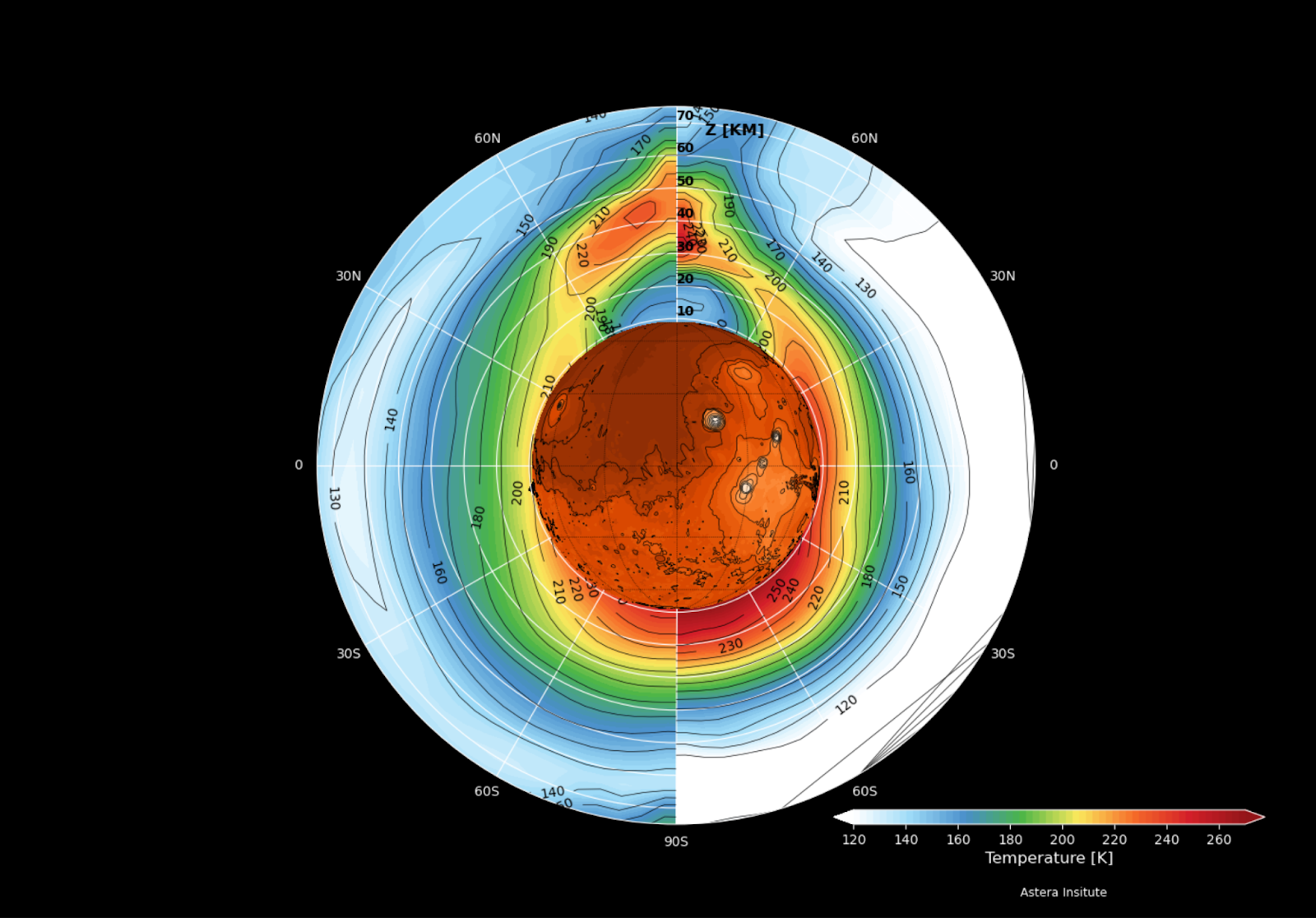
It’s been understood for over 50 years that there would be two steps to making Mars more Earth-like: first warm the planet up to allow photosynthesis, which is relatively quick and easy, then build up the oxygen level using photosynthesis. We’re looking at the first step, surface warming.
Mars is too cold for stable liquid water — the average temperature is around 210 K (about -60º C), and atmospheric pressure is only ~6 millibars. Warming the planet by 30 – 50°C could melt near-surface ice, enabling surface habitability and photosynthesis. There are lots of ways to warm Mars, including greenhouse gases and orbiting mirrors. Our team at Astera is investigating a warming approach based on engineered aerosols — specifically, nanoparticles that can forward-scatter sunlight and block thermal infrared. Compared to greenhouse gases, they’re four orders of magnitude more mass-efficient. That kind of efficiency matters — you want to get the biggest radiative payoff. If we want to make progress in this century, we need to use the materials that are already readily available on Mars, rather than shipping them in.
Along with the simulation work and delivery prototyping that we’re doing at Astera, we are working with collaborators at Northwestern University to batch-manufacture and test the most promising particles. This work is part of an extended collaboration involving scientists from Aeolis Research, JPL, the University of Central Florida, MIT Haystack Observatory, and the University of Chicago Climate Systems Engineering Initiative, among other institutions.

What properties of aerosols lead to warming the planet, rather than cooling it?
On a clear-sky night when we can see the stars, it’s typically cooler than on a cloudy night. So clouds (a form of aerosol) act as a warm blanket. Clouds also bounce sunlight back to space (cooling effect). For any aerosol, the net effect (warming minus cooling) depends on the size, shape, and composition of the aerosol. To warm Mars, we need to choose/design a combination of size, shape, and composition that gives a strong warming effect.
We also need to pay attention to particle mass. In our recent Science Advances paper, we showed that certain nanoparticle designs can achieve the same warming effect as fluorocarbon gases (a particularly potent greenhouse gas), but with ~50,000 times less mass. That matters, because even with the improved launch economics we’re seeing, getting mass to Mars is still expensive, so we need to keep the particle factory as lightweight as possible.
How would these nanoparticles be made?
The current concept involves dispersing nanoparticles into Mars’ atmosphere, where they remain aloft for long periods. These particles — which could include graphene disks or metal ribbons or even natural salts — selectively scatter shortwave solar radiation while blocking outgoing infrared. This alters the radiative balance, raising surface temperatures.
We’re exploring multiple production pathways. For example, it may be possible to fabricate aerosols using materials from Mars regolith, or using Mars’ CO2-rich air as the feedstock for making graphene disks as a byproduct of oxygen production. For a solar-powered graphene production, the basic ingredients for warming Mars could be Mars’ air and sunlight.
Particles also have another advantage: they start working within months and stop working when removed. That makes the system controllable and potentially reversible. So we could switch off or adjust a well-designed intervention as warming proceeds.
We hear your team has already made advances on researching particles 👀
Yes! One of our researchers, Alex Kling, developed an open-source screening tool to assess the warming efficiency of different particle types. It’s motivated in part by a conversation at the Tenth Mars conference, where Mars climate researchers agreed we needed something like this for natural aerosols as well. And I hope it will also be used by exoplanet researchers. Natural aerosols can be really important in extending the habitable zone, in both warming and cooling directions (for example, the type of high altitude organic haze found on Saturn’s moon Titan can be really effective in cooling a world’s surface).
Our tool is already available on GitHub, and it’s forming the basis for our next set of experiments. You can find it here:
We’re also going to batch-manufacture and test particle interactions and production protocols — essentially, answer questions like, how hard is it to make these materials from scratch? What kinds of impurities or degradation modes do we need to model? And we’ll continue sharing our results openly through preprints, on Zenodo, and on Substack.
Why is it important to do this work as open science?
Making all our findings public is necessary for informing a spacefarer’s consensus about what to do with those findings. The Outer Space Treaty says, “The exploration and use of outer space […] shall be the province of all humankind,” and every country has signed up to that.
Because we’re starting a new field, we have to work in a way that others can plug into. We have to seed open standards, protocols, and cultural momentum now, to create infrastructure that enables many organizations to work on terraforming in parallel. We’re building tools, datasets, and protocols that others can test, benchmark against, and improve. That includes publishing aerosol designs, experimental methods, and model inter-comparison frameworks — both the successes and the failures. We need to create a foundation that the whole research community can build on. And culturally, this aligns with NASA’s approach — raw rover images are public as soon as they arrive — and it’s a model that’s worked well for decades.
How do you think about the ethical questions that arise from a proposal to terraform Mars?
Perhaps Mars should remain untouched, as a planet-sized wilderness park that people bypass on our way to the stars? Or we could see Mars as an environmental restoration problem: undoing the collapse of a once-habitable planet?
Personally, I think a night sky full of living worlds is better than one that’s dead. Mars is Galactic gardening for beginners. If Mars is lifeless, then there’s no ecosystem to protect, and creating a new one might be the most meaningful thing we could do with it. But more work is needed to search for life on Mars, and decisions about Mars’ future should be made within a democratic framework. Any serious terraforming effort would take decades, if not centuries. On those long timescales, our politics and our worldviews will change. What won’t change are the basic scientific constraints, and it’s the science that we propose to study.
How can people learn more?
You can read the essay with Robin Wordsworth or check out our latest technical study. And keep an eye out for our forthcoming technical Substack!

Throughout a meandering career in government, academia, policy think tanks, startups, and investing, I have spent a lot of time thinking about what stalls progress and what to do about it to catalyze a more abundant future. I’m thrilled to have joined Astera to put this into practice by leading our strategic investments in the visionary science and transformative technologies that can yield an abundant future.
What excited me most about coming to Astera was the opportunity to develop a theory of where to deploy our philanthropic resources. Astera’s values and broad approach provide a framework for how we are going to deploy capital — efficiently, catalytically, creatively, boldly. But what we invest in could take many forms. We want our philanthropy to increase human flourishing, innovation, abundance, transformative science, and other abstract ideals. But there is no “human flourishing store” we can walk down to to make a purchase. We have to deploy resources into specific projects. Which ones? Why?
Any theory we develop to answer these questions will be iterative, subject to continual feedback and refinement. We expect to have some failures and to talk openly about the lessons we learn along the way. And yet I do think there is a good meta-framework for thinking about these issues. Last year I had the privilege of speaking at the Progress Conference 2024. My talk focused on explaining the causes of the Great Stagnation. Some of my charts were pretty grim — I called it the Dark Steven Pinker portion of the talk — but I ended on a more optimistic note: a way forward for the progress movement.
It’s a three-pronged approach involving technoeconomics, sociopolitics, and entrepreneurship.
Technoeconomics refers to the study and analysis of how technological capabilities and constraints interact with economic factors — like costs, productivity, and market dynamics — to shape the feasibility, performance, and adoption of technologies to grow the economy. What technologies are technically feasible and economically viable? How badly do customers want them? How do changes in input costs, learning curves, or performance metrics affect competitiveness? What is the optimal configuration of a system given technological and economic trade-offs?
These questions are critical if we want to have a concrete vision of the future we are trying to build. It’s one thing to say that a good future should include abundant energy. But if we are going to actually build a future with abundant energy, we need to start developing some definite opinions about which sources of energy can contribute in what ways. What are our projections for solar deployments? Can nuclear fission ever be cheap again? Why is it so expensive in the first place, given that it was so cheap in the 1970s? What about geothermal and fusion? What variants of each are most promising? How do solar and batteries fit into this?
Only after we engage with these kinds of questions will we have a basis for steering resources into energy technologies. We need to start with a concrete vision, and technoeconomics is the way to get one.
Thanks for reading Human Readable! Subscribe to receive news and updates from Astera Institute.
Sociopolitics refers to the intersection and interaction of social and political factors in shaping institutions, decisions, and outcomes. Technoeconomics tells us what’s fundamentally possible and what customers want, but sociopolitics is the source of cultural and institutional barriers to what is possible—what the rest of society wants. What kinds of innovations will be culturally rejected or refused by regulators or other institutions? What kinds of innovators and innovations are rewarded with money or status?
The ways that sociopolitical issues impact innovation start far upstream in the scientific process. Where does the funding for scientific and technological innovation come from? What are the incentives that these funding and reward mechanisms create for the kinds of questions that are asked in the first place? With our open science policy, we made the decision to defund journal publication, in part because journals create an incentive to develop polished narratives instead of discovering useful truths. As a science and technology funder, we are acutely aware of the shortcomings of other funding sources and also of how hard it can be for us to skillfully deploy funding. What are we tacitly incentivizing? How do we account for the fact that people tell us what we want to hear? We won’t always get everything right, but we are committed to grappling with these questions and working to foster institutions that are aligned with our mission of supporting visionary science and transformative technology.
Many people think of entrepreneurship as the activity of setting up a business. I like a different definition I got from Tom Kalil. Tom says that an entrepreneur is someone who is not limited by resources under direct control. An entrepreneur finds a way to get the job done while outperforming what they “should” be able to do with their starting resources. You can be a business entrepreneur, but you can also be a philanthropy entrepreneur or a science entrepreneur.
Resources are not just money. They are whatever is required to overcome the problems identified in the technoeconomics and sociopolitics part of the analysis. Projects require buy-in from all kinds of stakeholders, not just funders — what does it take to achieve that buy-in? For Astera to be unreasonably successful, we need to persuade the world’s most innovative scientists and technologists to work with us in sometimes unconventional ways. And we also need to catalyze change in other philanthropic organizations in the process. True success requires us to be entrepreneurial.
I believe that applying these three lenses will serve us well as we decide what kinds of projects to fund to drive transformative scientific and technological change. But — surprise! — it’s also what I think we should look for in the teams we support. We are looking for teams with ambitious and concrete ideas for what a compelling future could look like (technoeconomics), who are clear-eyed about the nontechnical challenges their projects may face (sociopolitics), and who have a relentless determination to surmount those challenges (entrepreneurship).
These attitudes are not the default in science and technology. What’s more common is an indefinite, nonspecific sense that the future will be better or worse. When there is a concrete vision, it is often not accompanied by an interest in engaging with the work required to instantiate it. And with the first two elements lacking, entrepreneurship in science and technology often takes on a performative, going-through-the-motions form.
If you are a scientist or technologist with a concrete vision for a better future, an intense interest in the obstacles to actualize it, and an unflagging drive to make it happen, please reach out. I’d love to hear from you.

In Abundance, Ezra Klein and Derek Thompson make the case that the biggest barriers to progress today are institutional. They’re not because of physical limitations or intellectual scarcity. They’re the product of legacy systems — systems that were built with one logic in mind, but now operate under another. And until we go back and address them at the root, we won’t get the future we say we want.
I’m a scientist. Over the past five years, I’ve experimented with science outside traditional institutes. From this vantage point, one truth has become inescapable. The journal publishing system — the core of how science is currently shared, evaluated, and rewarded — is fundamentally broken. And I believe it’s one of the legacy systems that prevents science from meeting its true potential for society.
It’s an unpopular moment to critique the scientific enterprise given all the volatility around its funding. But we do have a public trust problem. The best way to increase trust and protect science’s future is for scientists to have the hard conversations about what needs improvement. And to do this transparently. In all my discussions with scientists across every sector, exactly zero think the journal system works well. Yet we all feel trapped in a system that is, by definition, us.
I no longer believe that incremental fixes are enough. Science publishing must be built anew. I help oversee billions of dollars in funding across several science and technology organizations. We are expanding our requirement that all scientific work we fund will not go towards traditional journal publications. Instead, research we support should be released and reviewed more openly, comprehensively, and frequently than the status quo.
This policy is already in effect at Arcadia Science and Astera Institute, and we’re actively funding efforts to build journal alternatives through both Astera and The Navigation Fund. We hope others cross this line with us, and below I explain why every scientist and science funder should strongly consider it.
Journals are the Problem
First, let me explain why this is such a big deal to those who are new to this issue. It might seem like publishing is a detail. Something that happens at the end of the process, after the real work of science is done. But in truth, publishing defines science.
The currency of value in science has become journal articles. It’s how scientists share and evaluate their work. Funding and career advancement depend on it. This has added to science growing less rigorous, innovative, and impactful over time. This is not a side effect, a conspiracy, or a sudden crisis. It’s an insidious structural feature.
For non-scientists, here’s how journal-based publishing works:
After years of research, scientists submit a narrative of their results to a journal, chosen based on field relevance and prestige. Journals are ranked by “impact factor,” and publishing in high-impact journals can significantly boost careers, visibility, and funding prospects.
Journal submission timing is often dictated by when results yield a “publishable unit” — a well-known term for what meets a journal’s threshold for significance and coherence. Linear, progressive narratives are favored, even if that means reordering the actual chronology or omitting results that don’t fit. This isn’t fraud; it’s selective storytelling aimed at readability and clarity.
Once submitted, an editor either rejects the paper or sends it to a few anonymous peer reviewers — two or three scientists tasked with judging novelty, technical soundness, and importance. Not all reviews are high quality, and not all concerns are addressed before editorial acceptance. Reviews are usually kept private. Scientific disagreements — essential to progress — rarely play out in public view.
If rejected, the paper is re-submitted elsewhere. This loop generally takes 6–12 months or more. Journal submissions and associated data can circulate in private for over a year without contributing to public discussion. When articles are finally accepted for release, journals require an article processing fee that’s often even more expensive if the article is open access. These fees are typically paid for by taxpayer-funded grants or universities.
Several structural features make the system hard to reform:
- Illusion of truth and finality: Publication is treated as a stamp of approval. Mistakes are rarely corrected. Retractions are stigmatized.
- Artificial scarcity: Journals want to be first to publish, fueling secrecy and fear of being “scooped.” Also, author credit is distributed through rigid ordering, incentivizing competition over collaboration. In sum, prestige is then prioritized.
- Insufficient review that doesn’t scale: Three editorially-selected reviewers (who may have conflicts-of-interest) constrain what can be evaluated, which is a growing problem as science becomes increasingly interdisciplinary and cutting edge. The review process is also too slow and manual to keep up with today’s volume of outputs.
- Narrow formats: Journals often seek splashy, linear stories with novel mechanistic insights. A lot of useful stuff doesn’t make it into public view, e.g. null findings, methods, raw data, untested ideas, true underlying rationale.
- Incomplete information: Key components of publications, such as data or code, often aren’t shared to allow full review, reuse, and replication. Journals don’t enforce this, even for publications from companies. Their role has become more akin to marketing.
- Limited feedback loops: Articles and reviews don’t adapt as new data emerges. Reuse and real-world validation aren’t part of the evaluation loop. A single, shaky published result can derail an entire field for decades, as was the case for the Alzheimer’s scandal.
Stack all this together, and the outcome is predictable: a system that delays and warps the scientific process. It was built about a century ago for a different era. As is often the case with legacy systems, each improvement only further entrenches a principally flawed framework. It’s time to walk away and think about what makes sense now.
What We’ve Learned So Far
We’re in a bit of a catch-22 as a scientific community in that we don’t have a solution to jump to, but we also can’t develop one well if we continue with journals. Prohibiting journals is our deliberate forcing function as we support such development at Astera and The Navigation Fund. By removing journals as an option, our scientists have to get more thoughtful about how, when, and why they publish. We’ve started to see some shapes of the future.
We began this as an experiment at Arcadia a few years ago. At the time, I expected some eventual efficiency gains. What I didn’t expect was how profoundly it would reshape all of our science. Our researchers began designing experiments differently from the start. They became more creative and collaborative. The goal shifted from telling polished stories to uncovering useful truths. All results had value, such as failed attempts, abandoned inquiries, or untested ideas, which we frequently release through Arcadia’s Icebox. The bar for utility went up, as proxies like impact factors disappeared.
Peer review has also become better and faster for us at Arcadia. It’s a real mechanism for improving our rigor, not a secret editorial gate. We often get public feedback, and we use it to openly improve our work in real time. Another recent example of accelerating public peer review was a study about room temperature superconductivity that was released in 2023, got bombarded on twitter, and was then countered by several independent validation studies in less than a month. The controversial work happened outside of journals, and it wasn’t just peer reviewed, it was peer tested. Evidence-based community consensus happened at lightning speed.
It’s important to note that you don’t have to opt-out of academia to try something new. Astera recently funded a major structural biology project involving multiple academic groups, and the scientists enthusiastically agreed to forge a path without journals. It has been a delightful experience to think more clearly with them about the true impact of their work. The potential outcomes have to be so valuable for what they are — in this case, scalable X-ray crystallography methods that advance our understanding of how proteins move — that they transcend journal proxies. Expansive, iterative reuse of their methods is a more worthwhile goal than shiny comments from three anonymous reviewers. Those are the kinds of ambitious projects we like to fund.
Pre-prints are also a great way for anyone to participate now. And we need scientists to experiment with more radical formats. Pre-prints still maintain many journal features and are typically released close-in-time to journal articles, for which they are ultimately designed. In contrast, digital notebooks designed for computational work, such as Jupyter, allow for entirely different paradigms of publishing. Arcadia and others are now playing around with ways to automate conversion of such notebooks to publishable, dynamic outputs that can self-update as linked data evolves (see here, here, and here).
These experiences have converted me completely. I can’t unsee this new world. I look forward to making that true for more people by helping them take the first step.
What Could Happen Next
So how do we start? It’s important to define core publishing requirements before trying stuff. In 2016, a group of scientists, publishers, and funding agency representatives put forth the FAIR (Findable, Accessible, Interoperable, and Reusable) Principles, and they can be summarized as follows:
- Findable means we can discover stuff across digital space and time. Published items need to be linked to information about their creators and a long-lasting unique identifier, like a DOI (or Digital Object Identifier).
- Accessible means that you can easily find and search for publications using normal things like Google scholar or even ChatGPT. There shouldn’t be extra barriers, like paywalls, to finding published work.
- Interoperable means that you should be able to connect information across different formats and venues, which will only get more important as we leverage more AI tools over time.
- Reusable means that it’s possible for others to build on published work, which requires information and permissive licenses.
Work also needs to be permanently archived so that it’s accessible in the long term, which is not a new problem and remains largely unsolved. We especially need to figure this out for large datasets and repositories that the community relies on.
Scientists should probably be putting out shorter narratives, datasets, code, and models at a faster rate, with more visibility into their thinking, mistakes, and methods. In this age of the internet, almost anything could technically be a “publishable unit.” It doesn’t even have to sound nice or match the human attention span anymore, given our increasing reliance on AI agents.
In more general terms, we need publishing to be a reliable record that approximates the true scientific process as closely as possible, both in content and in time. The way we publish now is so far from this goal that we’re even preventing our own ability to develop useful large language models (LLMs) that accelerate science. Automated AI agents can’t learn scientific reasoning based on a journal record that presents only the glossy parts of the intellectual process, and not actual human reasoning. We are shooting ourselves in the foot.
What Could Be Possible
What are some practical non-journal options for publishing available now? Many FAIR options exist outside of journals today that are ready to go, and we wrote up our recommendations for Astera scientists recently.
However, we are far from achieving what’s possible. In addition to the many issues inherent to journal processes, it’s a system that was never designed to scale with our needs today. When journals first emerged in the 17th-18th century, they were responsible for handling outputs from hundreds of scientists. In 2021, a UNESCO report estimated that there’s approximately 9 million full-time researchers around the world that publish millions of articles across about 40,000 journals.
It’s also not possible to architect a viable alternative system in a vacuum without users to iterate with. We urgently need more scientists to try strategies that stretch our imagination for what the future could hold. Below are just a few ideas that could be fun to explore:
- Tools to automate the finding and collating of peer review, wherever it lives, e.g. published reviews, comments, social media, meeting notes, conferences, reuse of the science in the real world, etc.
- Ways to directly share lab notebooks and rely on LLMs to dynamically organize and synthesize information, over time. These outputs can be customized based on the readers’ interests.
- LLMs or knowledge graphs that help anyone quickly landscape scientific areas, flag conflicting data, or quantitatively score the novelty of new studies.
- Autonomous agents that can analyze actual data to generate new hypotheses propose alternative interpretations of published conclusions.
- The ability to connect reviews with real world outcomes at a later point-in-time through betting markets or interpretability work on different autonomous agents.
I don’t know if these are the right ideas, which is why we need to try them. But all of these ideas ladder up to giving both authors and readers more agency and optionality to meet their own needs. You drive your own content. You can curate and assess science without an editor. And everyone doesn’t necessarily need to agree on a single, centralized solution. Today’s technologies allow for a multitude of strategies that can be layered on top of the internet and augmented over time. We can have choices.
Towards a Better Return-on-Investment
You might think that scientific publishing would be too costly to revamp, even if we had clear solutions. But journal-based publishing already costs the global scientific community $10-25 billion per year for subscriptions and article processing fees, most of which are paid for using taxpayer-funded grants. In addition, a conservative estimate of millions of scientist hours are spent on journal publications annually. Currently, a significant portion of the science community outside the U.S. can’t even afford to participate via journals.
This is an expensive price to pay in exchange for an unreliable record, immeasurable delays, opportunity costs, and degradation of public trust. I cannot think of a worse return-on-investment for scientists, science funders, and society than continuing to enable journal publishing.
We don’t need to wait for permission to fix this. The future of science is not going to be rescued by journals or legacy institutions. We need to reclaim science’s role in serving society. I often hear scientists say they can’t abandon journals because they will lose their funding. As a funder, I’m letting you know that we’re not just comfortable with new publishing strategies, we require it.
If our approach sounds exciting to you, send us your ideas, apply for funding, and participate in our experiments. If you’re a fellow science funder, I’d love for you to join us in holding the line for change.
Seemay Chou is Astera’s Co-Founder and Interim Chief Scientist.

When Dakota Gruener first began her career in global health policy, she was driven by a simple but powerful question: what are the biggest levers we can pull to improve human wellbeing? In pursuing that question, she’s traveled across continents and disciplines, from vaccine access in Cameroon to digital identity systems in Bangladesh. After a stark revelation about climate displacement, she’s now taking on one of the most complex and controversial frontiers in climate science: sunlight reflection.
Today, as a Resident at the Astera Institute, Dakota leads Reflective, a research organization focused on evaluating the science, risks, and governance of methods that could reflect sunlight away from Earth and potentially cool the planet. We sat down with her to explore her approach, why sunlight reflection demands urgent research, and what it means to pursue climate solutions that could prove essential, even when they come with a great deal of unknowns.
Read the full interview on our Substack: https://asterainstitute.substack.com/p/reflecting-on-and-for-our-future

When Thomas Teisberg began deciphering Earth’s ice sheets, he didn’t expect to find himself nestled in a metaphorical pyramid. With a background in electrical engineering and experience in drone perception systems, he’d been building the tools that collect data used to understand melting ice sheets. But over time, he began to see this work as the bottom layer of a pyramid of activity. He started to become more interested in the layers above — not just the layers of ice — but also the models, projections, uncertainty, and real-world decisions that rest on that foundational data.
Now, as a Resident at the Astera Institute, Thomas is working to close the loop between ice sheet data collection and modeling, with the end goal of enabling better decision-making around sea-level rise. We sat down with him to hear more about how he’s approaching this massive systems problem, why improving uncertainty matters, and the opportunities he sees to catalyze change for the future.
Read the full interview on our Substack: https://asterainstitute.substack.com/p/breaking-the-ice
In the early 1990s, NASA was ready to fund a project that would generate 15 TB of images of the night sky. This was a massive amount of data for the time. It was the beginning of the first era of big data in science, where scientists and funders could invest in big projects to collect large data sets for many people to use.
But actually using that data required more than just the telescopes that NASA could fund. The data needed to be stored, curated, retrieved, and analyzed. The Alfred P. Sloan Foundation — a private philanthropy — contributed not only to the telescopes, but also contributed successive grants for the open data release, community, infrastructure, and management that was needed to turn the massive dataset of images into something transformative for astronomers.
This kind of data-intensive science (DIS) advanced not just astronomy, but also computer science and core software tools for scientific database management and data analysis. Microsoft computer scientist Jim Gray, who led the database software work of the Sloan Digital Sky Survey, was a strong advocate for it. Gray recognized that DIS is a fundamental evolution of the scientific method: scientific innovation, as a process, is radically altered by massive scale compute and large, complex datasets.
We are poised for an explosion in scientific discovery through DIS. Across a wide range of scientific disciplines, the cost of data generation is dropping. Data generation now leverages cheap sensors, robotics and automation, which drive smaller, cheaper, and higher throughput methods to make data. At the same time, the cost of data storage and processing also continues to decline. As a result, we can now create datasets of ever increasing size at lower and lower costs, and connect them to larger and larger models built through machine learning. We’re entering a world in which large, well-curated datasets enable us to predict scientific outcomes computationally before we test them empirically.

We’re not ready.
Without a change in how we organize scientific research itself, we won’t be able to use these developments in data generation and modeling at scale. Science is often organized around the laboratory, the principal investigator, and the publication, rather than data, software, and computational power. This approach creates different cultures between institutions and scientific disciplines, and affects their usage of computation, collaboration, and ability to scale.
New ways of performing science with data at a massive scale will look quite different from the ‘one lab, one hypothesis’ experiments we are familiar with. Gray’s work on the Sloan Digital Sky survey intentionally separated data capture, data curation, and data analysis into distinct categories with their own funding, technology, labor forces, incentives, and goals. These distinct categories accelerated the team’s capabilities to fundamentally accelerate astronomical discoveries.
DIS goes far beyond simply increasing the scale of data generated. This is illustrated by the Human Genome Project and the Mars Rovers missions. While they might seem fundamentally different, these initiatives shared starting goals of obtaining more data at a scale that seemed impossible. And each quickly arrived at the same conclusion: more data means scientists need to perceive data and work with that data through software, which requires more processors, more metadata, more software engineers — and more collaboration.
And while the infrastructure for data creation, storage, and analysis is exponentially growing, the cultural infrastructure of how we fund and collaborate in science hasn’t kept pace. There is a colossal opportunity to test novel systems to support the scientific research process — systems that integrate rapidly scaling technologies.
It’s also an opportunity that requires scientists to be better at collaborating with each other in their day to day work. The systems that drive science today frequently reward single investigators running laboratories at academic institutions, who receive tenure and funding based on their publication metrics in elite scholarly journals. Those systems, which sit at the heart of so much American science, combine data capture, curation, and analysis, keeping all three inside the same labs, labor forces, and technological environments. Combining these activities cuts against the collaborations required for DIS; it’s partly why even data projects essential to their fields can result in conflict, rather than collaboration.
The opportunity is ripe for funders of science to invest in new systems of data capture, curation, and analysis that are built on the foundation of DIS. These new kinds of investments will generate public data goods that could speed up the pace of scientific discoveries in measurable ways. We envision this data-centric way of doing and funding science as an iterative system: data is funded through feedback from scientists and published as a core good for many scientists, who then form networks of users. Their needs then inform the next iteration of core data goods that receive funding.
This is far easier said than done. The cost of data generation is still high, even with trends driving it down. Cloud computing has costs that bite, especially when compared to the costs of using local machines that are often hidden in overhead. This leads to questions about capital constraints: How do funders make smart choices about capital deployed to support DIS? Where does data live over the long term? How can funders validate that users are actually addressing their scientific problems at hand? We have to rethink what success looks like in scientific funding, not just pay for data at scale.
Falling in love with problems
Many champions have hailed the value of generating and sharing large amounts of data to advance science. The Open Science movement, of which I have enthusiastically been a part of for two decades, has advocated for opening up datasets generated by the traditional infrastructures of science that follow a ‘one lab, one problem, one dataset, one grant’ approach. While the movement has very successfully changed government policies across the world to open up this data, relying on individual labs working towards individual papers has led to a gulf between data creators and data users.
Data curation, our best bet to close that gulf, is rarely funded in ways that are adequate to enable DIS to emerge. Data publishing has been siloed, has led to repository proliferation, and has created data discovery problems. And data at scale is often simply too expensive to download and upload for systems of collaboration that require copying and redistributing data to work. As a result, DIS is mostly happening at the edges of many sciences, and not at the center for funders or research institutions.
In contrast, DIS succeeds to the extent that it allows the exploration of many solutions by many people across many points in time. Instead of asking “How does this data solve this specific problem?” we ask “How does this data increase our ability to create new models and predictions across a wide range of inquiry?” In many ways, this looks a lot more like a software product approach — it’s an iterative, human-centered process to test and validate hypotheses around proposed solutions.
The central concept of iteration — characterized by rapid prototyping, frequent testing, incremental improvements, and user feedback loops — can significantly reshape how large scientific datasets are generated and funded. Funders could build projects that release early MVP datasets to validate experimental methods, explore how much data is truly needed at scale, and refine metadata. This iterative approach reduces upfront risk and improves outcomes through early feedback. It also allows us to build modular datasets that allow new data layers to be added over time as data generation technology evolves.
DIS puts more responsibility on the funder of science to be creative partners with scientists. Funders have the scale, leverage, and incentives to generate data and measure its impact beyond what an individual lab can do. But that capacity also needs to come with the recognition that most scientists don’t live in a data-intensive system, and therefore don’t have the time, funding, and resources to build DIS systems without meaningful change. There’s a huge opportunity for funders to close that gap by devoting time and resources to the systems that enable DIS.
Doing the experiment
At Astera, one of our tenets is “Do the experiment.” A concrete example of how we’re trying to implement this iterative approach in our data program at Astera is in our microbial data work. Rather than starting by negotiating five years of data generation, curation, and analysis with a bunch of long-term research grants to elite academic institutions, we’re probing the field with a request for information, talking to the scientists who responded (currently underway), and looking to build a data MVP through a contract research structure.
We’ll then use that MVP to help understand what data is actually most informative for scientists trying to predict microbial phenotype from microbial genotype: is it tens of thousands of microbes with a little bit of data each? Is it a few hundred microbes with an exhaustive amount of data each? Is it somewhere in between? What can we learn about the individual data types if we experiment with knocking rows and columns out of the data product? How much data does it take to make predictions more accurate? Most importantly — what does this do for scientific discovery, and how can we use that information to inform our decisions to scale the data over time?
I’ve long been an advocate of open science systems. But as a funder I’ve translated that into a strong belief in DIS investments — with particular emphasis on data generation and curation. This move has come with a shift in mindset that holds great potential for the field of scientific discovery. It obliges us to think differently than we would with a traditional grantmaking approach, which is often optimized for the ‘one-lab, one grant’ system. It is time to invest in data goods that are built iteratively from the beginning to create value for many users, support deep curation to empower them to solve many problems, and drive model building to enable predictive science. This is how we get closer to our overall goal of accelerating the pace of and capacity for scientific discovery.
Contracts and business deals aren’t necessarily the first things that come to mind when you think about solving challenges in biotech and pharma, but they are a critical step in the process of commercializing new technology. Technical founders and leaders rarely learn about these crucial bottlenecks to their success until they are trying to navigate a large organization and understand the risks of particular contract terms.
Andy Coravos and Abby DeVito experienced this first-hand as leaders of HumanFirst, who built an intelligence platform for clinical research that was acquired by ICON (NASDAQ: ICLR) in 2024. Negotiating, signing, and expanding their first contracts was incredibly challenging, but they found support along the way from people willing to share their successful contracts and tips for understanding the pharma industry. Together with their legal collaborator, Shu Hu, they have built a pharma and biotech sales handbook for software founders with insights about understanding the pharma development process and organizational structure, as well as tactical advice on pricing, negotiating, and contracts.
At Astera, we are eager to support others who can transform their hard-won insights into public goods that enable others who are building new technologies. You can find links to this handbook and other resources for startups and nonprofits on our website. Please reach out if you have insights and tools to share for guiding science and technology toward greater impact!
Applications are now open for our Fall cohort, due May 7
We are thrilled to announce the inaugural cohort of Astera Institute’s Residency Program! Following our open call earlier this year, we’ve selected an exceptional group of scientists, engineers, and entrepreneurs who embody our mission of creating public goods through open science and technology. This pioneering cohort brings together visionaries working across cutting-edge domains: advancing brain-machine interfaces to enhance human cognition, studying reflective cooling technologies to address climate change, creating sophisticated and accessible models of Antarctic and Greenland ice sheets to improve climate predictions, exploring terraforming methodologies for Mars, and developing functional foods based on the health benefits of fermentation.
Each resident will spend the next year at our Emeryville, CA campus pursuing these ambitious projects. These individuals are tackling challenges that are systematically underaddressed by traditional funding mechanisms, creating open tools and resources that can benefit humanity at scale. We’re particularly excited by how this cohort has embraced the program’s core principles of openness and experimentation, high-impact potential, and future-focused thinking. In the coming months, we’ll be sharing more detailed profiles of each resident and their projects, highlighting how their work contributes to our vision of leveraging open science for public benefit in areas critical to our planetary future and human flourishing.
Building on this momentum, we are excited to open applications for our Fall Residency cohort, starting October 2025! If you’re interested in joining us, apply here before May 7, 2025.
Meet the Residents

Chongxi Lai – Building brain-like models
Chongxi Lai works at the intersection of neuroscience, artificial intelligence (AI), and brain-machine interfaces (BMIs). Originally trained as an engineer, he transitioned to neuroscience to investigate the biological roots of intelligence. He earned his PhD through a joint program between the University of Cambridge and the Howard Hughes Medical Institute’s Janelia Research Campus. Returning to Janelia as a research scientist, Lai developed the first map-based hippocampal BMI enabling rats to navigate virtual spaces using neural activity alone, providing groundbreaking evidence of abstract spatial thought in animals. His research has revealed key parallels and distinctions between biological intelligence and modern AI algorithms, leading him to believe that AI architectures must evolve to be more like those of animals and humans. This evolution will lay the groundwork for AI and the brain to mutually enhance each other.
Project description
The rapid growth of AI intelligence is transforming what machines can do, pushing humans to enhance their cognitive abilities to keep up. One promising solution lies in developing advanced brain-machine interfaces (BMIs) capable of both reading from and writing to the brain, enabling the transfer of powerful knowledge representations from pre-trained AI models into biological brains. However, this requires a deeper understanding of intelligence, hardware development, and extensive animal testing, a challenge made difficult by the vast range of possible approaches and limited prior research. Meanwhile, advances in large-scale GPU computing and simulation tools now allow testing of brain enhancement in virtual environments, which might greatly reduce the search space. Towards this goal, Lai’s research program focuses on building a brain-like model within a simulated environment, where it is tested across a range of cognitive and embodied tasks. This model will serve as a baseline to test whether and how cognition can be enhanced through novel AI-assisted BMI closed-loop stimulation algorithms.
Learn more: Detailed Project Description
Open roles: AI Research Engineer – Brain-Inspired AI & Neural Enhancement

Dakota Gruener – Studying sunlight reflection to limit climate impact
Dakota Gruener leads Reflective, a non-profit climate initiative accelerating the pace of sunlight reflection research. Across a career spanning global health, digital privacy, and climate, Dakota has focused on developing frontier technologies with the potential for worldwide impact—while ensuring the risks they pose are addressed responsibly. Originally trained in biology and political science, she served as aide-de-camp to the CEO of Gavi, the Vaccine Alliance, where she supported negotiations with vaccine manufacturers and helped raise $10B to fund five years of vaccine programs in low- and middle-income countries. She was also founding Executive Director of ID2020, a global alliance committed to ethical, privacy-protecting digital identity and served as co-chair of both the WHO Smart Vaccine Certificate Working Group, which set international standards for COVID vaccination certificates, and the Good Health Pass Collaborative, a private-sector initiative (125+ companies) focused on resumption of international travel. Dakota holds a degree from Brown University and is a proud Californian.
Project description
Sunlight reflection may be the only available option, alongside dramatic emissions reductions, adaptation, and rapid scaling of carbon removal, to rapidly limit many climate impacts over the coming decades. But we don’t know nearly enough about it to make a scientifically-informed decision about potential deployment – and we’re not on a trajectory for rapid, legitimate decision making. Reflective is a philanthropically-funded initiative to develop the necessary knowledge base and do the requisite technology research and development, urgently and responsibly.
Learn more: www.reflective.org

Edwin Kite – Warming Mars
Edwin Kite is a planetary scientist working on habitability across our solar system and beyond. As an associate professor at the University of Chicago and participating scientist on the Mars Curiosity rover, he combines computer modeling, spacecraft data analysis (Mars orbiters and space telescopes), rover operations, and terrestrial analog fieldwork. Originally from London, Edwin holds undergraduate degrees from the University of Cambridge and a PhD from UC Berkeley, and has held previous roles as O.K. Earl Fellow at Caltech and Hess Fellow at Princeton.
Project description
We don’t know what our future in space will look like. Perhaps we’ll leave the planets as wildernesses and live in large space stations. Or perhaps we’ll adapt lifeless worlds to be more suitable for life. While the cost of access to space is falling rapidly, surprisingly little research has been done on Mars terraforming since the pioneering work of Carl Sagan and Chris McKay. For Mars, warming the surface is a necessary first step in making it suitable for life. Kite’s team will investigate novel methods for warming Mars, exploring the fundamental physical constraints that will shape future decisions about the planet. The aim is to identify critical measurements needed for informed decision-making, accelerate technical progress, and grow an interdisciplinary research community.
Learn more: Feasibility of keeping Mars warm with nanoparticles

Erika DeBenedictis – Designing life for Mars
Erika is a former astronomer and current synthetic biologist. As an undergraduate at Caltech, Erika worked on topics in computational physics including space mission orbit design at NASA and computational protein design at D. E. Shaw Research. Erika worked with Kevin Esvelt at MIT during her PhD, where she used laboratory automation to tackle problems in synthetic biology. She led an academic lab at the Francis Crick Institute in London, UK focused on using Robotics-Accelerated Evolution to push the limits of biotech for use on Earth and in Space. In 2021 she founded Align to Innovate, a nonprofit improving the reproducibility, scalability, and shareability of life science research with programmable experiments. Erika is now the CEO of Pioneer Labs, a nonprofit that engineers microbes for Mars.
Project description
Biology is the ultimate green technology, capable of upcycling waste into food, water, and air: all the essentials for human life. However, today it is too unreliable, untested, and wasteful to be a mission-critical technology. That’s why Pioneer Labs is engineering hardy critters that perform gracefully even in the extreme conditions of space. Pioneer Labs engineers microbes that the first astronauts will use on Mars to upcycle waste into essentials like food, therapeutics, and building materials. By doing so, they aim to make biomanufacturing ubiquitous, reliable, and green — on Earth and beyond.
Learn more: Polyextremophile engineering: a review of organisms that push the limits of life
Open roles: Computational Biologist

Rachel Dutton – Accessing the health benefits of fermented foods
Rachel is a microbiologist and leader in the study of fermented food microbiomes. Originally trained as a bacterial geneticist with Jonathan Beckwith at Harvard Medical School, she pioneered the use of fermented foods like cheese as simplified microbial ecosystems to help reveal how more complex microbiomes work. As a Bauer Fellow at Harvard University and then a Professor of Biological Sciences at UC San Diego, she led research to grow microbiomes in the lab and probe how microbes interact and evolve within communities. Rachel moved to Arcadia Science in 2022 to build new models for doing science, and continues to build towards expanding our understanding of fermented foods at Astera.
Project description
Humans have co-evolved alongside fermentation, and fermented foods offer profound health benefits for the gut and immune system. Rachel’s research focuses on making these benefits more accessible by uncovering how microbes and their byproducts support human health, such as reducing chronic inflammation. By mapping the connections between microbial species, their metabolites, and health benefits, her work lays the foundation for developing next-generation functional foods. The open-source datasets generated through this research aim to accelerate discovery across academia and industry, helping to democratize knowledge and transform how fermented foods are used for preventative health.
Learn more: Building Scientific and Microbial Communities

Thomas Teisberg – Modeling the earth’s ice sheets
Thomas Teisberg is an engineer and radio glaciologist, developing open-source tools for data collection and modeling of the Earth’s ice sheets. He recently finished his Ph.D. in Electrical Engineering with the Stanford Radio Glaciology group, where he developed open-source ice-penetrating radar systems and explored scientific applications of automated airborne radar surveys. With previous work ranging from radar systems for self-driving cars to acoustic sensing systems for Zipline’s medical supply delivery UAVs, Thomas has planned and participated in two field seasons of testing UAV-borne radar systems in Greenland, as well as participating in fieldwork on glaciers in Svalbard and Iceland. He was the recipient of a NASA FINESST grant, as well as being a TomKat Graduate Fellow, a Stanford Data Science Scholar, and a Stanford Human-Centered Artificial Intelligence (HAI) Graduate Fellow. Thomas also developed and maintains radarfilm.studio, an open-source data portal for the first-ever continent-scale radar surveys of the Antarctic and Greenland ice sheets.
Project description
Ice sheet models are crucial numerical simulation tools used to understand the internal dynamics and future state of the Greenland and Antarctic Ice Sheets, providing future projections of Earth’s ice sheets that are a core component of predicting sea level rise. These models link many levels of cryospheric, atmospheric, and ocean sciences, but technical challenges restrict who can practically run and reproduce state-of-the-art models. Even as large-scale computational resources have become more widely available, the complexity of porting tools between systems, the lack of common dataset descriptions, the reliance on initialization know-how, and other challenges have continued to limit the reproducibility and accessibility of large-scale ice sheet models, creating roadblocks to other kinds of much-needed research.
This project aims to break down technical barriers to ice sheet model reproducibility, helping to pave the way to better incorporation of observational data and open interdisciplinary research. It aims to tackle both the technical challenges, building tools and documentation to make sharing models easier, and the non-technical challenges, working with academic partners to produce examples and best practices for reproducible research.